Java Reference
In-Depth Information
Age
C2
Income
Age
C1
Income
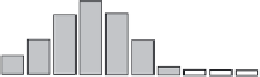
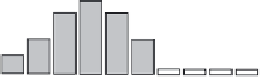
Figure 4-9
Cluster histograms.
techniques, it may also be possible to interpret clusters directly in
three-dimensional space. However, when there are 10s, 100s, or 1,000s
of attributes, it is not humanly possible to identify the clusters present
in the data. This is where data mining comes in. Clustering algorithms
automatically identify groups of cases into clusters. Humans can then
inspect these clusters, looking either at the centroids themselves or at
rules that define the clusters. For example, the rules for clusters C1
and C2 from the example in Figure 4-8 may look like
C1: 0 < income < 50,000 AND 0 < age < 35
C2: 40 < income < 100,000 AND 31 < age 57
Note that there is overlap between the regions defined by C1 and
C2. Cases that fall into this overlapping region may actually be closer
to one centroid than another, as determined by a distance measure.
Sometimes a case may be equally close to multiple clusters, in which
case the probability or confidence associated with the assignment to
any one of these clusters may be equally low.
What constitutes similarity between cases depends on the type of
attributes involved. When considering numerical values, such as
income, it is quite easy to determine “closeness” since we can graph




Search WWH ::

Custom Search