Java Reference
In-Depth Information
Attributes
Response?
1 = Yes,
0 = No
Age
Cust_id
Income
#Children
HeadHH
…
1001
1002
1003
1004
30,000
55,000
25,000
50,000
30
67
23
44
2
3
0
1
Y
N
N
Y
1
1
0
0
Cases
X
1
X
2
X
m
Y
. . .
Target
Attribute
Predictor Attributes
Case Identifier
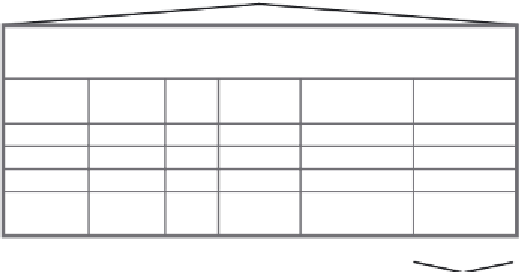
Figure 4-1
Characterization of a dataset used for classification.
values for the predictors and target in each
case
. Additional
attributes, such as
name
or some
unique identifier
, may be provided to
identify each case. The resulting model creates in effect a functional
relationship between the predictors and the target:
Y =
f
(X
2
, ..., X
m
).
Determining the quality of classification models is based on
comparing the historical, or
actual
, target value with the
predicted
value. Chapter 7 explores specific metrics used to assess classifica-
tion model quality.
Algorithms that support classification in JDM are decision trees,
naïve bayes, support vector machine, and feed forward neural net-
works.
4.3
Regression
Regression is used to make predictions for continuous numerical
targets. It is valuable, for example, in financial forecasting, time
series prediction, biomedical and drug response modeling, house
pricing, customer lifetime value prediction, and environmental
modeling such as predicting levels of CO
2
in the atmosphere.
Like classification, regression is a supervised mining function and
requires the build data to contain a set of predictors and a target
attribute, as illustrated in Figure 4-2. The target attribute contains












Search WWH ::

Custom Search