Hardware Reference
In-Depth Information
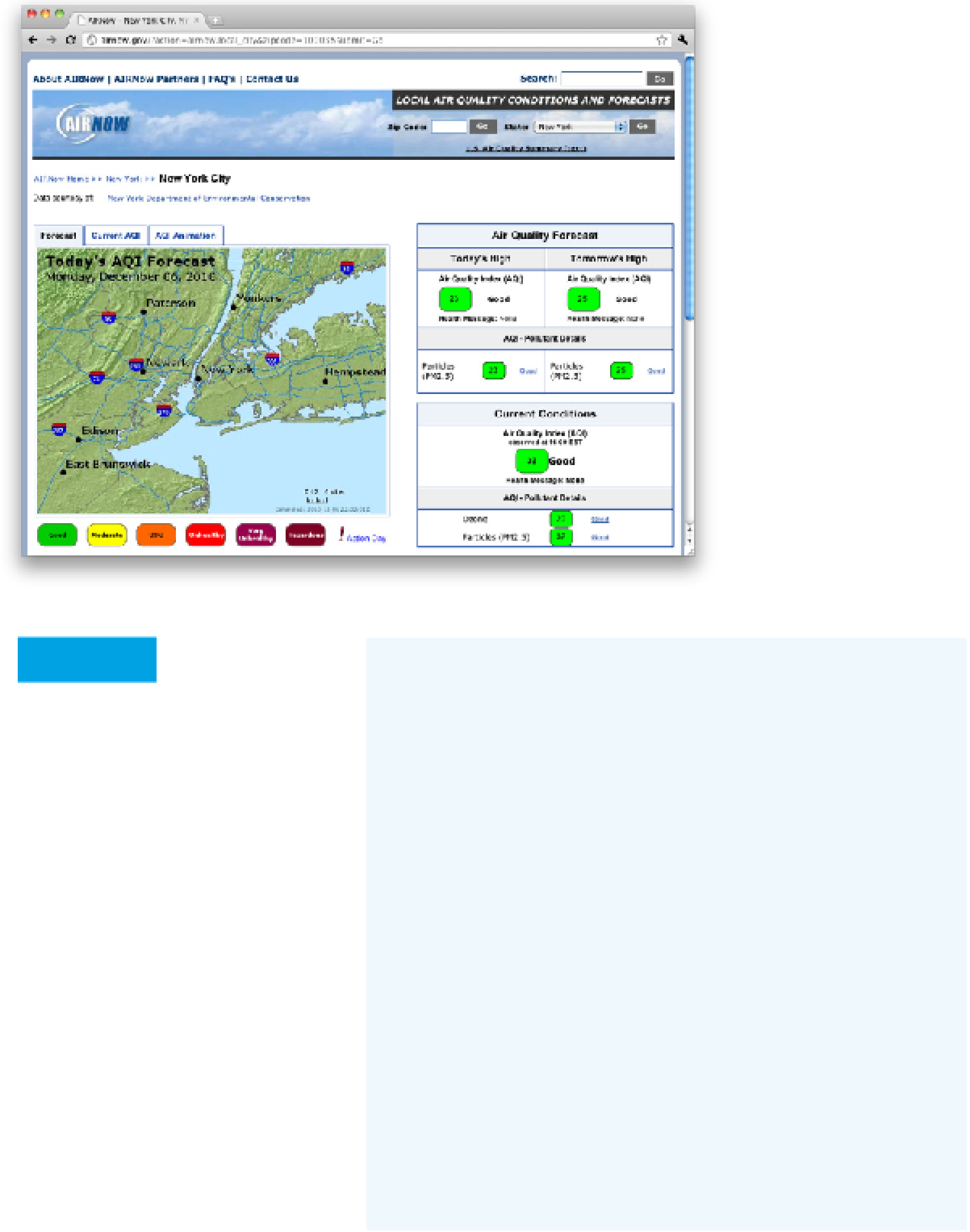
Figure 4-10
AIRNow's page is nicely laid out
for scraping. The PHP program
used in this project ignores the
ozone level.
Fetch It
This PHP script
opens the AIRNow
web page and prints it line by line. The
fgetss()
command reads a line of text
and removes any HTML tags.
<?php
/*
AIRNow Web Page Scraper
Context: PHP
*/
// Define variables:
// url of the page with the air quality index data for New York City:
$url =
'http://airnow.gov/index.cfm?action=airnow.showlocal&cityid=164';
When you save this file on your web
server and open it in a browser, you
should get the text of the AIRNow page
without any HTML markup or images.
It's not very readable in the browser
window, but if you view the source
code (use the View
Source option in
your web browser), it looks a bit better.
Scroll down and you'll find some lines
like this:
// open the file at the URL for reading:
$filePath = fopen ($url, "r");
// as long as you haven't reached the end of the file:
while (!feof($filePath))
{
// read one line at a time, and strip all HTML and
// PHP tags from the line:
$line = fgetss($filePath, 4096);
echo $line;
}
// close the file at the URL, you're done:
fclose($filePath);
?>
Current Conditions
Air Quality Index (AQI)
observed at 17:00 EST
45
These are the only lines you care about.