Information Technology Reference
In-Depth Information
1 - break (strong negative)
2 - hurt (weak negative)
3 - neutral (unknown or don't care)
4-help(weakpositive)
5 - make (strong positive)
Fig. 6.
Qualitative scale for measuring softgoal contributions
(“correspondence” and “conflict” areas shown in Fig. 4b). We associate softgoals
with stakeholders' personal constructs, and use the tasks that contribute to these
goals as elements that stakeholders can rate using their constructs. The key idea
is to compare the stakeholders' constructs by how they relate to a shared set of
concrete entities, rather than by any terms the stakeholders use to describe them.
In this way, we avoid making any assumptions about the meanings of individuals'
constructs. Four highly iterative and interactive activities are involved in our
framework: extraction, exchange, comparison, and assessment. We now describe
each step in more detail using the media shop example described in Sect. 2.
Extraction
:
Given a set of goal models, we need to extract relevant information
within some context to identify constructs and elements for grid analysis. A key
underlying assumption of PCT and RGT is that elements define the context.
Elements need to be carefully chosen to be within the range of convenience of
the constructs we wish to study [10]. For instance, it bends our minds to consider
“antique” or “modern” numbers and “prime” or “non-prime” furniture.
When analyzing goal models, we begin with some core agent or key activities
in the system, and this generally provides a well-scoped area of interest. We
carefully record the context of each grid so that sensible and relevant exchange
and comparison can be performed.
Softgoals are candidate aspects and are often di
cult to express in a measur-
able way, so it is hard to ensure that different stakeholders understand them in
the same way. Softgoals within the context are selected as personal constructs,
and each construct is identified as a pair of polar extremes corresponding to
“make the goal” and “break the goal”. Concrete entities of the same type (e.g.,
tasks), which are related to the chosen constructs, are selected as elements. The
reason is twofold. First, empirical evidence suggests that people are better at
comprehending and making analogies between concrete concepts rather than
abstractions in RE [33]. Second, heterogeneous elements are likely to result in
range of convenience problems as well as decreasing the validity of the grid [10].
Each element is then rated on each bipolar construct. For each grid, some rat-
ings can be obtained from the goal models directly, some can be derived through
label propagation algorithms [5], and the remainder need to be completed by the
stakeholder. A five-point scale is defined in Fig. 6 to make such measures both
subtle and specific. This multi-rating scale captures softgoals' satisficeability:
softgoal fulfillment is relative and “good enough” rather than absolute [5].
The goal models shown in Figs. 2 and 3 share the media shop context, and
the extracted tasks and softgoals from these strategic rationale models are listed


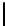






Search WWH ::

Custom Search