Database Reference
In-Depth Information
6.2 Fitting and Measuring the Accuracy of Our Ranking Model
The evaluation of our learning model comprises: ensemble method selection,
number of
estimators
, sample size for learning, and inputs' relative importance.
In this subsection, we aim to evaluate the most important settings and tune
our model towards higher accuracy, using the learning framework described in
Subsect.
3.3
.
Selecting and Fitting an Ensemble Method.
Ensemble methods have
become very popular in statistical learning. Their algorithms combine several
estimators
or
week learners
to provide robust learning models and prevent
overfitting. We fit and evaluate our model with three methods from Scikit-
learn library: Random Forest(RF), Extremely Randomized Trees(ET),
and Gradient Tree Boosting(GB). We consider two distinct samples with
124,000 lines each, one for training and other for testing. We set to 10 the
number of estimators as a common setting. All other parameters have default
settings. Based on four metrics detailed on Subsect.
6.1
, Random Forest fits
our model better. Figure
5
depicts three of these metrics. Random Forest per-
forms particularly well in nDCG score, the main metric for ranking problems.
While Extremely Randomized Trees and Gradient Tree Boosting score
0.9126 and 0.4128 respectively, Random Forest scores 0.9594. In terms of pre-
cision, Random Forest slightly better, with a score of 0.9922. Extremely
Randomized Trees scores 0.9899, and Gradient Tree Boosting scores
0.9502. It also outperforms the other two methods regarding the mean square
error metric, scoring 0.0094 compared to 0.0122 with Extremely Random-
ized Trees
and 0.1021 with Gradient Tree Boosting. nDCG(2) metric
Fig. 5.
Ensemble methods evaluation:
Random Forest(RF), Gradient
Tree Boosting(GB) and Extremely
Randomized Trees(ET).
Fig. 6.
Overhead for different number of
estimators of Random Forest.


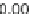


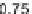































































































Search WWH ::

Custom Search