Database Reference
In-Depth Information
simply to the speed of the slowest node, but to the speed of the fastest node
relative to the slowest node.
Expanding this example shows us that in order for our cluster to be able
to achieve a performance improvement with 3
tasks per worker, the fastest
node would have to be able to compute at least one of the slowest node's tasks;
meaning that the fastest node would have to complete three tasks before the
slowest node could finish two tasks. Note that the turnaround time in this case
will then depend on the ability of the fastest node to complete four tasks, but
that it is sucient to complete three tasks before the slowest node completes
two tasks. This is because once three tasks have been completed by the fastest
node it will be free to request, and receive, more work from the Master which
will prevent the slowest node from receiving that same work. In this scenario,
the fastest worker node would have to be just over 1.5 times the speed of the
slowest worker. In addition to this, there would need to be enough faster nodes
in the cluster to be able to prevent all of the slower nodes from requesting an
additional (third) task.
Because of this, for a traditional coarse-grain data split, initial upgrades to
the cluster (even upgrading half of the cluster to machines with faster processors
and twice as many cores) does not improve matrix multiplication performance.
Overall application performance depends on stragglers on slower nodes, and the
coarse grain split precludes straggler mitigation. Upgrading most (75 %) or all
of the cluster to Faster nodes does improve performance.
N
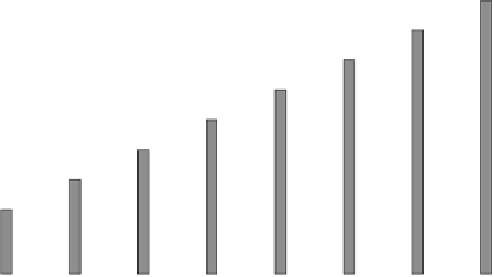
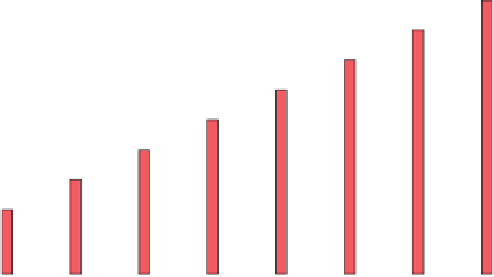
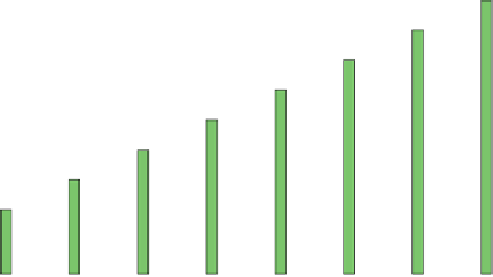
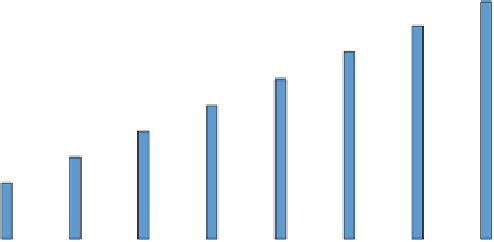
Fig. 1.
Execution time for the traditional one-task-per-worker initial data split, for
different problem sizes (groups of bars along the x-axis) and cluster upgrade levels
(one bars in each group, as per the in-graph legend).

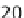
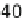



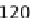















































Search WWH ::

Custom Search