Information Technology Reference
In-Depth Information
Therefore, we conclude that SVM feature
weights in combination with Manhattan distance
fulfill the necessary constraints for a learning task
distance measure based on feature weights.
experiments, we can tackle this problem in a sim-
pler way. Since we know all training taxonomies
in advance, we can extract a large feature set for
several prototypical training taxonomies. We then
perform a feature selection to determine the best
feature set for each learning task. Using only a
small subset of base features
X
B
we regard the ad-
ditionally selected features as the set of specially
extracted features
X
\
X
B
for each learning task.
Additional experiments for synthetic data can be
found in Mierswa and Wurst (2005).
We used the benchmark dataset containing
39 user made taxonomies (Homburg, Mierswa,
Möller, Morik, & Wurst, 2005). The taxonomies
were split into a training set of 28 taxonomies
and a test set of 11 taxonomies. For both, a set of
flat binary classification tasks was generated by
splitting the items at each inner node according
to subconcepts. As stated before we selected the
set of optimal features for each of the learning
tasks using a wrapper approach (forward selec-
tion) in combination with a nearest neighbor
learner evaluated by 10-fold cross validation. We
used classification accuracy as the optimization
experiments
In this section, we evaluate the ability of our
approach to speed up the extraction of essential
features, while the accuracy is preserved. As
mentioned before, finding the optimal feature set is
a very demanding task which must be performed
for each unknown learning task anew. For our
Table 5 Average accuracy and effort for learn-
ing using base features, optimized features and
feature transfer (ft)
Accuracy
Time
O p t i m i z a t i o n
cycles
base features
0.79
-
-
optimal features
0.92
42s
3970
ft (k = 1)
0.85
3s
257
ft (k = 3)
0.88
5s
389
ft (k = 9)
0.89
8s
678
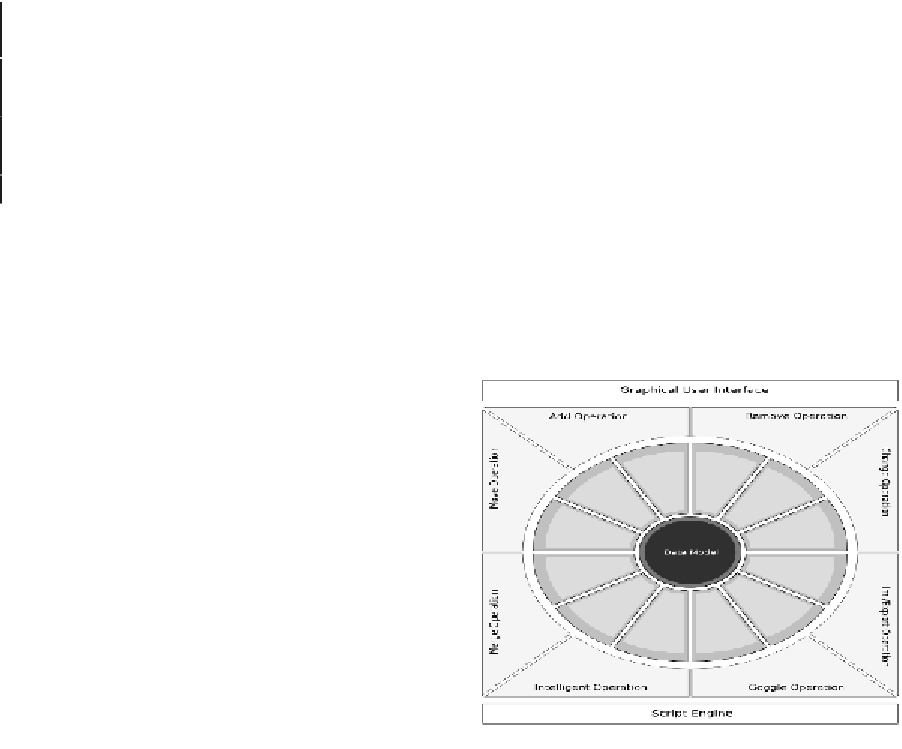
Figure 13. Architecture of Nemoz: the core is the
data model; the service layer accesses the data
model implementing various functions; the ap-
plication layer around provides developers with
generic operations; the GUI interacts with the
user, the ScriptEngine with the developer
Figure 12. The base feature weights of the audio
test cases after a dimensionality reduction on
two dimensions











Search WWH ::

Custom Search