Environmental Engineering Reference
In-Depth Information
Fig. 4.3
Adaptive cluster sample. The initial sample is a random grid sample of 16 square plots
(
a
). In the successive stages the four neighbouring plots of a selected plot are added to the sample
if this plot contains at least one polluted site (
b
)
satisfy a specific criterion, for instance concentrations exceeding a specific thresh-
old concentration, e.g. a soil quality standard (Fig.
4.3
). This type of sequential
sampling leads to spatial clustering of sampling locations. This can be efficient if
locations with concentrations exceeding the threshold concentration are strongly
clustered. For details I refer to Thompson and Seber (
1996
).
4.2.2 Estimation
The formulas for estimating the (parameters of) the SCDF and for estimating their
sampling variances generally differ between the sampling designs. I have seen sev-
eral studies in which some “smart” sampling design was applied, but after collection
of the data, the surveyors apparently forgot about this design, and estimated the
parameters and their variances as if it were a SI sample. This is not proper science.
The sampling design determines the selection (inclusion) probabilities of sampling
locations and of pairs of sampling locations, and these selection probabilities must
be accounted for in estimating the parameters and their variances. Hereafter, formu-
las for estimating the spatial mean (Section
4.2.2.1
), areal fraction (proportion of
the area) with concentrations exceeding a threshold concentration (Section
4.2.2.2
),
SCDF (Section
4.2.2.3
), and percentiles (Section
4.2.2.4
) are given for the three
sampling designs described in the previous section.
4.2.2.1 Spatial Mean
Simple Random Sampling
For SI the spatial mean is estimated by the unweighted mean of the measurements
in the sample
































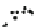








































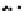








































Search WWH ::

Custom Search