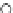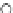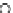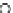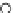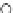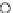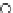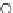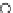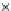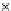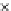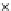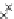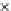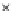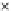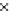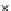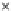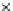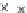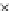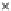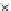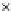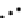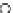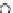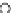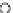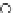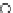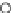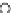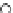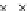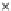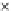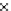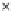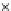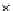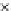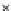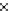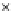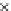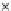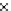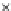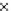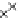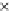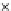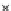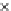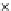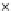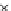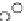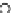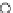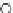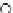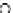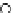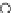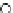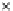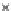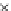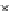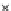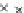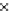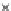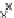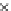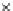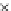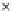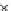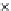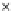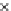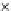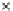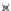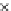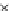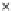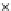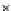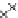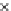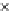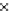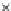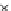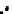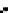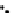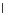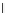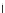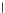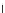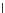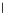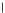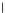Information Technology Reference
In-Depth Information
We now present an experiment with 200-instance training and test datasets
(100 instances per class) and apply the (Shannon) MEE gradient descent
algorithm with
h
=1(fat estimation) and
η
=0
.
001. Fig. 3.21 shows the
evolution of the decision border and the error PDF (computed only at the
e
i
values) at successive epochs. Note the evolution towards a monomodal PDF,
as the position of the circle center is being adjusted. Fig. 3.22 shows the
converged solution. In the final epochs the radius of the circle undergoes the
main adjustments.
3
0.25
x
2
^
E
(e)
2
0.2
1
0.15
0
−1
0.1
−2
x
1
e
0.05
−2
0
2
4
−2
−1
0
1
2
(a) Epochs=0
3
0.25
x
2
^
E
(e)
2
1
0.2
0
0.15
−1
−2
x
1
e
0.1
−2
0
2
4
−2
−1
0
1
2
(b) Epochs=32
3
0.35
x
2
^
E
(e)
2
0.3
1
0.25
0
−1
0.2
−2
x
1
e
−2
0
2
4
−1
0
1
2
(c) Epochs=52
Fig. 3.21 Two-class Gaussian datasets at different epochs of the MEE-trained
circle. The left graphs show the datasets with the circular decision border (solid
line). The right graphs show the error PDF in the
E
=[
−
2
,
2]
support.