Information Technology Reference
In-Depth Information
1
P
T|x
0.8
0.6
0.4
0.2
x
0
−2
−1
0
1
2
3
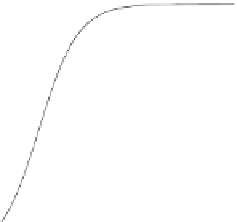
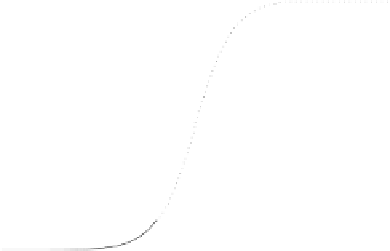
The posterior probabilities
P
T |x
, (solid line) and
P
T |x
Fig. 2.2
(dotted line) of
Example 2.2. The differences are barely visible.
For the
P
T |x
we have min
P
e
=0
.
317. By construction, the optimal split
point for the
P
T |x
is also 0.5 with a variation of the min
P
e
value of
P
−
1
1
|x
(
δ
)) = 0
.
023.
We then obtain a deviation of the error value quite more important than
the deviation of the posterior probabilities. For more complex problems, with
more dimensions, one may expect sizable differences in the min
P
e
values
between the ideal and real models, even when the PDF estimates are good
approximations of the real ones.
2
δ
(0
.
5
−
Relatively to Example 2.1, one should be aware that poor MMSE solutions
are not necessarily a consequence of using a direct parameter estimation
algorithm. Iterative optimization algorithms may also fail to produce good
approximations to the min
P
e
classifier, even for noise-free data. This was
shown in [32] for square-error and gradient-descent applied to very simple
problems.
The square-error function is a particular case of the Minkowski
p
-power
distance family
p
,p
=1
,
2
, ...
L
p
(
t
(
x
)
,y
(
x
)) =
|
t
(
x
)
−
y
(
x
)
|
(2.11)
We see that
L
SE
≡
L
2
.The
L
p
family of distance-based loss functions has
a major drawback for
p>
2: it puts too much emphasis on large
t
y
deviations, thereby rendering the risk too much sensitive to
outliers
(atypical
instances), reason why no
p>
2 distance function
L
p
has received much
attention for machine learning applications. The square-error function itself
is also sometimes blamed for its sensitivity to large
t
−
y
deviations.
For
p
=1, it is known that the regression solution to the estimation prob-
lem corresponds to finding the median of
Z
−
X
, instead of the mean. This
could be useful for applications; however, the discontinuity of the
L
1
gradi-
|