Information Technology Reference
In-Depth Information
100
4
90
3.5
80
70
3
60
50
2.5
40
30
2
20
10
1.5
0
0
50
100
150
200
250
300
50
100
150
200
250
300
Epochs
Epochs
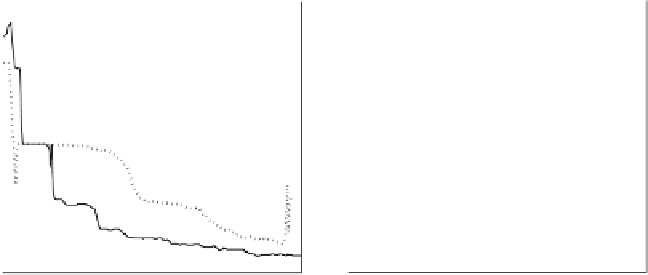
Fig. 6.8 Training Error (left) and Error Entropy (right) curves for FLR (dotted
line) and VLR (solid line) in the classification of a real-world dataset [205].
was attained when using VLR and moreover with a continuous decrease of
the error entropy.
6.1.2 The Batch-Sequential Algorithm
Error entropy estimation based on the Parzen window method implies using
all available error samples. The use of the batch mode in the back-propagation
algorithm is therefore obligatory. It is known, however, that the batch mode
— weight updating after the presentation of all training set samples — has
some limitations over the sequential mode — weight updating after the pre-
sentation of each training set sample [95]. To overcome these limitations
a brief reference to the possibility of combining both batch and sequential
modes when training neural networks was made in [26]. An algorithm com-
bining the two modes, trying to capitalize on their mutual advantages, was
effectively proposed in [202] and tested within the specific MEE scope with
Rényi's quadratic entropy: MEE Batch-Sequential algorithm, MEE-BS.
One of the advantages of the batch mode is that the gradient vector is
estimated with more accuracy, guaranteeing the convergence to, at least, a
local minimum. The sequential mode of weight updating leads to a sample-
by-sample
stochastic
search in the weight space implying that it becomes less
likely for the back-propagation algorithm to get trapped in local minima [95].
However, for EE risks one still needs a certain quantity of data samples to
estimate the entropy, and this limits the use of the sequential mode.
One way to overcome this dilemma, proposed in [202], consists of splitting
the training set into several groups that are presented to the algorithm in a
sequential way. The batch mode is applied to each group.