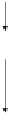Information Technology Reference
In-Depth Information
classification tasks. Besides Shannon's and Rényi's quadratic entropies of the
MLP errors we will also consider the ZED and EXP risks presented in the
preceding chapter.
We will use the back-propagation algorithm for the training procedure,
since it has a simple implementation which is an extension of the gradient
descent procedure described in Sect. 3.1.2. Although we use back-propagation
for convenience reasons, nothing in the MEE approach precludes using any
other training algorithm reported in the literature (such as conjugate gradi-
ent, Levenberg-Marquardt, etc.) and usually applied with classic risk func-
tionals such as MSE.
6.1.1 Back-Propagation of Error Entropy
The error back-propagation algorithm [192] is a popular algorithm for weight
updating of MLPs when these have perceptrons (also known as neurons)
with differentiable activation functions. It can be seen as an extension of the
gradient descent algorithm, presented in Sect. 3.1.2, to MLP intermediary
layers of perceptrons between inputs and outputs, the so-called
hidden layers
.
A complete description of the back-propagation algorithm can be found in
[95,26]. In the following we only present a brief explanation of this algorithm
with the purpose of elucidating its formulas for empirical entropy risks. We
restrict ourselves to the one-hidden-layer case; extension to additional layers
presents no special diculties.
Figure 6.1 shows a schematic drawing of a one-hidden-layer MLP. The
large circles represent perceptrons. The hidden-layer perceptrons receive in-
put vectors with components
x
im
which are multiplied by weights and sub-
mitted to the activation function; Figure 6.1 shows the
l
th hidden perceptron
with weights
w
ml
producing a continuous output
u
il
. This is multiplied by
weight
w
lk
, and together with other hidden-layer outputs, feeds into the
k
th
output perceptron. Each output with the known target variable generates
error signals used to adjust the weights.
ݐ
ݓ
ݑ
ݓ
ݕ
ݔ
݁
Fig. 6.1 The signal flow and the back-propagated errors (doted lines) in a one-
hidden-layer MLP.