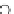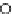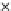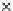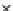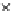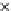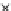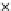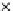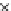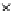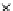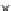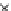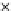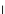Information Technology Reference
In-Depth Information
Example 5.4.
Consider two Gaussian distributed class conditional PDFs with
μ
−
1
=[0 0]
T
;
μ
1
=[3 0]
T
;
Σ
−
1
=
Σ
1
=
I
.
(5.19)
Independent training and test sets are generated with
n
= 200 instances (100
per class) and
R
ZED
is used with
h
=1and
h
=3.Aninitial
η
=0
.
001 is
used. Figs. 5.3 and 5.4 show the final converged solution after 80 epochs of
training: the final decision border and error PDF estimate;
R
ZED
and the
training and test misclassification rates along the training process. We see
that an increased
h
provokes a need of more initial epochs till
R
ZED
starts to
increase significantly. This is explained by looking to formula (5.17): a higher
h
implies a lower
∂ f
E
(0)
/∂w
k
and consequently smaller gradient ascent steps
(the adaptive
η
then compensates the influence of the higher
h
). On the other
hand, a better generalization is obtained with
h
=3.Infact,whenusinga
lower
h
the perceptron provides a better discrimination on the training set
(look to the decision borders of both figures) but with an increased test set
error. The use of a higher
h
provides an oversmoothed estimate of
R
ZED
,
masking local off-optimal solutions.
0.4
x
2
^
E
(e)
2
0.3
1
0
0.2
−1
0.1
−2
x
1
e
−3
0
−2
0
2
4
−2
−1
0
1
2
Error Rate (Test) = 0.070
0.4
0.8
^
Error Rate
ZED
0.35
0.6
0.3
0.4
0.25
0.2
epochs
epochs
0.2
0
0
20
40
60
80
0
20
40
60
80
Fig. 5.3
The final converged solution of Example 5.4 with
h
=1
.