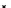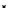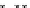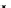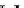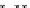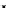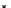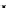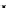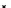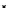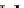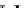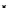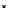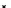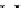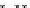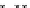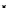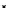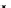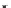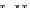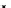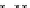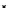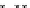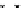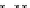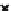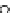Information Technology Reference
In-Depth Information
We have seen that the theoretical min
P
e
point in two-class univariate
problems coincides or is in a close neighborhood of the MEE point when
the class conditional distributions are not too overlapped, and corresponds
to max
P
e
otherwise, with the min-max turn-about value depending on the
distributions. The empirical MEE point also displays the same behavior, as
illustrated in Fig. 4.8 where SEE is shown for two different feature-class
combinations of the well-known Iris dataset [13]. In Fig. 4.8a the distribution
overlap is small and the MEE split point occurs close to the min
P
e
point. In
Fig. 4.8b, with large distribution overlap, the MEE split point occurs at an
end of the variable spanned interval, whereas the min
P
e
point occurs in the
vicinity of max SEE.
SEE
S
EE
1
1
0.8
0.8
0.6
0.6
0.4
0.4
0.2
0.2
x
1
x
2
0
0
4
4.5
5
5.5
6
6.5
7
7.5
8
2
2.5
3
3.5
4
4.5
Fig. 4.8 SEE curves for two splits of the Iris dataset (splitting the balls from the
crosses): a) class 1 (Iris setosa), feature
x
1
(sepal length): MEE at
x
1
=5
.
45
;b)
class 3 (Iris Virginica), feature
x
2
(sepal width): MEE at
x
2
=4
.
3
.
We will see later how to capitalize on the apparently annoying fact that
the MEE split point occurs at an end of the variable spanned interval for
overlapped distributions. As a matter of fact, we will use this interval-end
criterion as a synonym of “overlapped”.
Experimental studies consisting of applying the empirical MEE procedure
to artificially generated datasets, with known mutually symmetric distri-
butions, are expected to confirm the theoretical findings of the preceding
Sect. 4.1.2 and provide further evidence regarding the interval-end criterion
we mentioned. One such study was carried out for classes with Gaussian
distributions of the data instances in [152]. We present here a few more
results obtained following the same procedure as in the cited work, which
consisted of measuring the error rate and the interval-end hit rate of the
empirical MEE (for SEE) split point for equal-variance Gaussian distributed
data. Concretely, setting
σ
t
=1and
μ
0
=0,wevaried
μ
1
in a grid of points
and generated
n
normally distributed instances for both classes with those
parameters.