Information Technology Reference
In-Depth Information
algorithm was used to tune the membership function parameters. The proposed method can
be seen in Figure 1. The details of the proposed method are described in following sections.
Fig. 1
.
Flowchart of Proposed method
2.1 Fuzzy C-Mean clustering
In fuzzy clustering, each point has a degree of belonging to clusters, as in fuzzy logic, rather
than belonging completely to one cluster. To manage uncertainty in getting data quality and
accurate model, a new method known as the Fuzzy C-Mean (FCM) clustering is needed.
The FCM computes the distance measured between two vectors, where each component is a
trajectory (function) instead of a real number. Thus, this Fuzzy C-mean clustering is rather
flexible, moveable, creatable, as well as able to eliminate classes and any of their
combination. From the huge number of clustering methods, the fuzzy clustering was
focused on in the methodology of the present study since the degree of membership
function on an object to the classes found provides a strong tool for the identification of
changing class structures. Thus, the Fuzzy C-Means is used in order to build an initial
classifier and to update the classifier in each cycle; nevertheless, the methodology presented
can still be extended to any other techniques which determine such degrees of membership
(e.g. probabilistic clustering, etc.) [14].
Before the FCM could be utilized, the noise was removed from the dataset due to affect on
clustering data. Based on the statistic definition:
According to [15] a noise is considered to be more than three standard deviations away from
the mean which is formulated as below:
Noises = abs (object - MeanMat) > 3*SigmaMat;
In which, Meanmat is mean, SigmaMat is Standard deviation and abs is the functioning in
mathematic for Absolute value, i.e. instance: abs (-5) =5, which was implemented in
MATLAB software.
Fuzzy c-means (FCM) is a method of clustering which allows one piece of data to belong to
two or more clusters. The method developed by [16, 17] is frequently used in pattern
recognition. It is based on minimization of the following objective function:













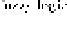















Search WWH ::

Custom Search