Information Technology Reference
In-Depth Information
No speed limit
Speed limit: 130 km/h
Classifier
0
200
400
600
800
1000
#cars
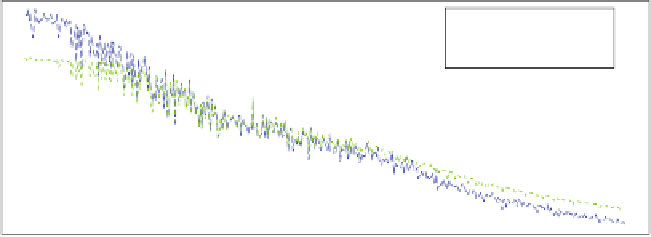
Fig. 3.
Comparison: Classifier vs. fixed actions
is not beneficial. As a first scenario, we thus want to learn the point from which
a homogenization in form of a speed limit of 130km/h leads to a higher mean
velocity of all cars in comparison to not setting a speed limit. The probability
for rear-end collision accidents decreases with an increasing homogenization of
trac. In our simulation, whenever two cars are involved in an accident, they
will be set to stay on the right lane for 600 iterations.
The simulation server is set up to let the simulation clients run experiments
with 4, 6, ... , 998, 1000 cars, each setting five times. The fraction of trucks is not
fixed, but its maximum is set to 10% of the number of cars. Each client places the
given number of cars on the road randomly and initiates the simulation according
to the scheme of Figure 2. After a settlement phase of 1000 iterations, recording
of the trac flow in cars per time at a defined point and the mean velocity of
all simulated cars in each iteration is started. After further 1000 iterations, the
state of the simulation is stored. A situation description is generated, using the
following features: Trac flow, trac density (sum of the vehicle lengths divided
by overall road length), mean velocity, standard deviation of velocity, and truck
percentage. The first action, in this case “no speed limit” is done and another
settlement phase of 1000 iterations follows. After this phase, the mean velocity
of all cars during further 1000 iterations is taken as fitness for the action.
Now, the saved simulation state gets restored and the next action gets inves-
tigated: “speed limit 130km/h” for the whole road. The fitness for this action
is computed analogously. The client then sends the state description and the
action with the highest mean velocity and the according fitness back to the
server. The server records all received results and lets the clients simulate until
the multitude of trac densities is run through.
The server uses an interface to
WEKA
[9] to build a classifier, when to use
which action. For learning, we use
WEKA's
J4.8 implementation of the
C4.5
algorithm [15]. The classifier is then tested on 494 new runs (with 4
,
6
,...,
1000
cars) of the same scenario and compared to the fixed usage of any of both