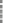Information Technology Reference
In-Depth Information
(a) State of the art conceptual model.
(b) Engineered reward-based model.
Fig. 1.
Concepts considered in this work
or as variants thereof [17]. Although existing models differ in some aspects, they
all share one commonality: the environment has to offer a state as well as a dis-
tinguished reward signal to the agent(s). Figure 1(a), based on the illustration
of Sutton and Barto [19], visualizes these signals in an agent system modeled as
Markov decision process (MDP, introduced later in Sect. 4).
To emphasize the inherent importance of both signals in the general case
consider the agent-internal components shown in Fig. 1(a). The components,
without being exhaustive, interact with each other in order to form a learning
agent. Here, the state signal is required for an appropriate state-action space
representation, e.g. in the form of a Q-Table [19]. It is also required to select
actions depending on the current state of the environment. The reward signal
constitutes an inherent feature of reinforcement-based learning algorithms in the
sense that agents aim at maximizing the expected return over time. Accordingly,
agents are required to be able to observe and to distinguish both signals.
3.2 Engineered Reward-Based Model
We will now propose an alternative conceptual model for reinforcement learning.
In this model, state features are not visible and the agent only observes one
signal—an engineered reward. Figure 1(b) visualizes this approach.
Starting from an MDP, the core idea is to design an engineered reward which
encodes original state and reward signals into a single value. The encoding hap-
pens on environment level either at runtime or during the process of designing the
engineered MDP. Then, the engineered reward is the only signal submitted to or
observed by the agent. Accordingly, the environment does not need to offer any
visible state feature to the agent and the agent itself is not required to sense any-
thing else but the engineered reward. Due to the encoding, however, the agent is
still able to obtain non-visible state information and the original reward. There-
fore, the used decoding (
dec
)/encoding (
enc
) approach needs to run in poly-
nomial time and formally has to ensure that
dec
(
enc
(
R
(
s, a
)
,s
)) = (
R
(
s, a
)
,s
)
holds, where
s
is an environment state from a set of states
S
,
a
is an action from
a set of actions
A
,and
R
:
is a reward function.
At the end of this section will present a concrete coding approach. For the
moment, however, we want to concentrate on the role of this concept in the
S×A →
R