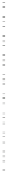Information Technology Reference
In-Depth Information
travel time cost
minimum cost
140
0.16
35
price 1
0.248
0.14
120
0.12
100
price 2
34.8
0.1
0.243
80
0.08
road users 1
34.6
60
0.06
0.238
road users 2
40
0.04
34.4
optimum
reward 1
reward 2
0.02
20
0.233
0
34.2
0
0
1000
2000
3000
4000
5000
0
1000
2000
3000
4000
5000
0
1000
2000
3000
4000
5000
Iteration
Iteration
Iteration
(a) Reward
(b) Price and road users
(c) Total travel time cost
Fig. 2.
Experimental results
For the price set, it is reasonable to assume
p
min
=0
, while to set
p
max
we rely on
the following reasoning. In general, a link in a road network is characterised by the
maximum number of road users that the link can accommodate,
μ
max
, expressed in road
users per
km
. In these experiments, we assume that a
1km
link cannot accommodate
more than 100 road users, and therefore
μ
max
= 100
. Given that, the maximum price
is set to
p
max
=
β
1
vμ
max
=
β
2
vμ
max
=0
.
03
v
.
In these experiments, we assume a value of time
v
of
, which is the average
hourly salary in Spain
1
, and therefore the maximum price for each link is
p
max
=
0
.
25e
8
.
36e
/
h
. Finally, we discretise the two price sets every cent of Euro, obtaining
P
1
=
P
2
=
{
0
.
00
,
0
.
01
,
0
.
02
,...,
0
.
25
}
.
For the average speed set, we discretise every
10 km
/
h
, obtaining
U
1
=
{
0
−
10
,
10
−
20
,
20
−
30
,
30
−
40
,
40
−
50
}
and
U
2
=
{
0
−
10
,
10
−
20
,
20
−
30
}
respectively. Given
that we generate a static quantity of road users, the sets
W
2
only comprise a
single time window, and therefore they can be removed from the state spaces of the two
market agents.
W
1
and
4.1
Results
For the evaluation, we run 50 experimental trials and we plotted the average of the fol-
lowing metrics: reward received by each agent, the price selected by each agent and
the corresponding number of road users that select each link, and the social cost in-
curred by the whole system. In these experiments, each agent uses Q-learning with
-greedy action selection [7] as learning method. After observing state
s
, the agent ex-
ecutes an action
a
and it observes again the environment state
s
and the reward
r
.The
agent uses these quantities to update the current action-value function
Q
(
s, a
)
,usingthe
formula:
Q
(
s
,b
)
− Q
(
s, a
)]
Q
(
s, a
)
← Q
(
s, a
)+
α ·
[
r
+
γ ·
max
b∈A
(18)
where
γ ∈
[0
,
1)
is the discount rate, and
α ∈
(0
,
1]
is the learning rate. In the exper-
iments, we set
α
=0
.
8
. These values have been experimentally
selected as those that gave the best results. For each state
s
, the learning agent selects
,
γ
=0
.
1
and
=0
.
1
1
http://ec.europa.eu/eurostat