Graphics Reference
In-Depth Information
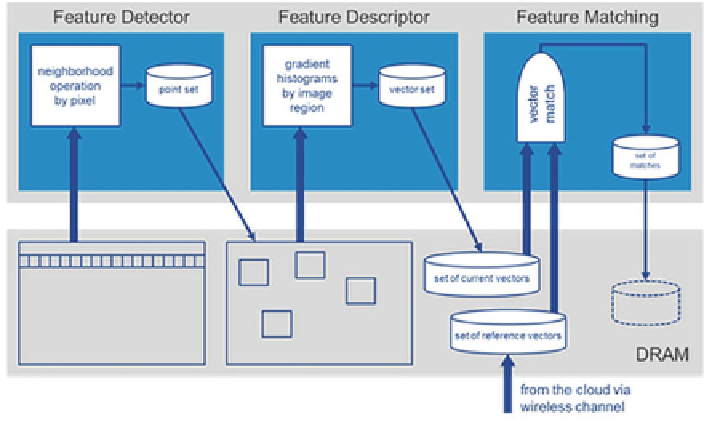
Fig. 7.15
Data locality of the feature tracking pipeline
Figure
7.15
shows the data locality in parts of the feature tracking pipeline shown
in Fig.
7.14
. Feature points are extracted from the entire image using a small neigh-
borhood that can be either (n+1)*(n+1), where n is an even number. For e.g., in a
3
3 neighborhood case every image line contributes three times to the calculation,
once as upper line, once as center line, and once as lower line. For an implementation
that is efficient in terms of external memory bandwidth, four line buffers should be
kept in local memory and operated as a ring buffer. Three lines contribute to the
current calculation and the fourth line is fetched in parallel by a DMA controller.
Feature descriptor calculations require a lot of random accesses in a larger area of
pixels around the feature point of interest. Here, the most effective implementation is
to store entire regions in local buffers. As the set of points is previously known from
the earlier step, the region that will be processed can be preloaded into an available
free buffer. Also, the memory accesses during full search in a database are deter-
ministic and can be exploited for effective prefetching of data by a DMA controller.
This means while comparing query to
entry[i]
one can already prefetch
entry[i+1]
.
When this data management is implemented properly, all the data are accessed once,
and thus computations will never have to be in the wait state for the data.
×
7.3.2 Memory Complexity
The memory subsystems of mobile system on chip (SoCs) are limited in terms of
bandwidth, due to limited pin count to connect to the external SDRAMs and due to
the priority to save power, which is mainly achieved by lower clock rates to external