Information Technology Reference
In-Depth Information
2.3 Temporal Dependencies in Compressed Video
Video encoders typically exploit three types of redundancies to reduce the compressed video
bit-rate, namely, spatial redundancy, temporal redundancy, and entropy. Spatial redundancy
refers to the correlation between pixels within the same video frame. This is also known
as intra-frame coding as only pixels within the same video frame are used in the encoding
process. The resultant encoded video frame, commonly called the I frame, can be decoded
independently.
Temporal dependency refers to correlations between adjacent frames. As the video captures
a snapshot of a video scene periodically at, say, 25 to 30 fps, adjacent frames will likely contain
very similar visual objects, often with some displacements due to motion of the objects or the
camera. Thus, the encoder can exploit this correlation by predicting a video frame from the
neighboring frames. In MPEG, for example, this is done through the use of predictive frames
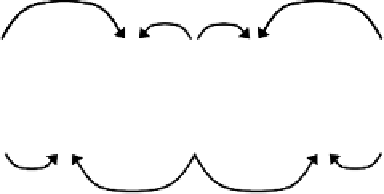
(P frames) and bi-directional predictive frames (B frames) as shown in Figure 2.4.
Specifically, beginning with an intra-coded I frame, the encoder will first predict the P frame
using a process called motion estimation. In motion estimation the encoder will search for
similar blocks of pixels in the I frame and the to-be-encoded P frame. After the search is
completed, only the displacement of the block (due to motion) and the prediction errors are
encoded to form the data for the P frame. Thus, P frames can be encoded using substantially
fewer bits than an I frame. This encoded P frame will then be used to predict the next P frame
and so on until another I frame is introduced.
In addition to P frames, a number of B frames are also introduced between a pair of anchor
frames (I or P frame). These B frames, as shown in Figure 2.4, are predicted from both anchor
frames to further reduce the resultant bit-rate. Therefore, B frames usually consume the fewest
bits compared to P frames and I frames in the same video stream. Both P and B frames are
called inter-coded frames. Note that, unlike I frames, P and B frames cannot be decoded
independently. Instead, the required anchor frames must first be decoded and then used in
decoding the inter-coded frames. This has two implications to media streaming.
First, as shown in Figure 2.4, the temporal dependencies dictate that the B frames cannot
be decoded for playback unless all two anchor frames are received and decoded. Thus, if
the media server streams out the video data according to their temporal order, the client will
need to buffer up B frames to wait for the second anchor frame to arrive before decoding for
the B frames can proceed. In practice, the video encoder often re-orders the frame sequence
according to the decoding order as shown in Figure 2.5 to reduce the client buffer requirement.
B
P
I
B
B
B
P
Figure 2.4
Temporal dependencies in compressed video











Search WWH ::

Custom Search