Information Technology Reference
In-Depth Information
All data blocks are sent to
r
0
d
N
-
h
-
1
r
h
-
1
d
0
d
1
. . .
r
0
r
1
. . .
c
i
,
1
c
i
,
h
-
1
r
0
computes all redundant data and
distributes them to all redundant nodes.
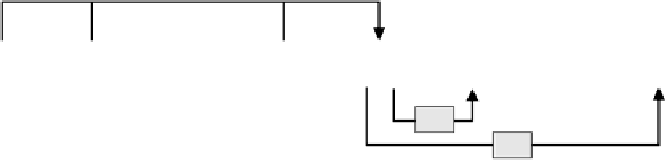
Figure 15.15
Update of multiple redundant nodes in the trivial redundant data generation algorithm
15.5 Multiple Redundant Nodes Update
In larger systems more than one redundant node will be needed to achieve good system relia-
bility. We can update the individual redundant data blocks in each parity group independently.
However, if we jointly update the multiple redundant data blocks, then it is possible to achieve
further savings. In the followingwe assume there are
N
nodes, of which
h
of themare redundant
nodes storing redundant data blocks.
15.5.1 Redundant Data Regeneration
We first consider the trivial redundant data regeneration algorithm (cf. Section 15.4.1) depicted
in Figure 15.15. Instead of repeatedly sending all data blocks to the redundant nodes
r
0
,
r
1
,...,
we can designate one of the redundant nodes, say
r
0
, to compute the redundant data for the other
redundant nodes
{
c
i
,
j
|
i
=
0
,
1
,...
;
∀
j
=
0
}
in addition to computing its own redundant data
{
c
i
,
0
|
=
,
,...
}
. This is possible as all the elements in the RSE code computation equation
(15.2) are already available. Afterwards it simply sends the computed redundant data blocks
to the appropriate redundant nodes, thereby saving a significant number of data movements as
shown in Figure 15.15.
For a media object of
B
data blocks, this algorithm will need to send
B
data bocks to
the redundant node
r
0
, which then sends (
B
i
0
1
h
)) computed redundant blocks to each
additional redundant node. Therefore, the total redundant data update overhead is equal to
B
/
(
N
−
h
)). Note that it is not necessary to designate a single redundant node to
compute all the redundant blocks. Instead we can divide the computations equally among all
the redundant nodes to balance the load and overhead across them. The resultant redundant
data update overhead will be the same.
On the other hand, if there is a central archive server storing a copy of all the media
data blocks, then it can regenerate locally all the updated redundant data blocks
+
(
h
−
1)(
B
/
(
N
−
{
c
i
,
j
|
i
=
0
and then transmit them to the redundant nodes (Figure 15.16).
In this case the redundant data update overhead is equal to
h
(
B
,
1
,...
;
j
=
0
,
1
,...,
h
−
1
}
/
(
N
−
h
)). Obviously this is
also the lower bound.









Search WWH ::

Custom Search