Database Reference
In-Depth Information
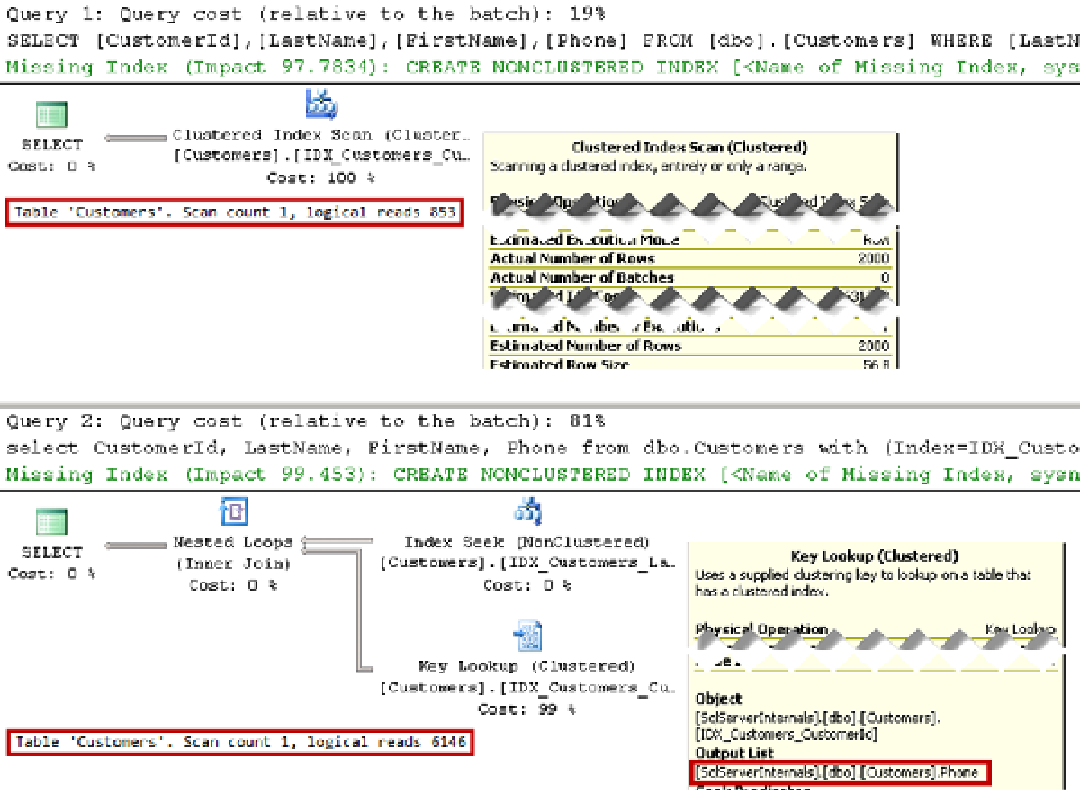
Figure 4-2.
Execution plans for the queries
As you can see, SQL Server correctly estimated the number of rows with the
LastName = 'Smith'
, and it decided
to use a clustered index scan instead of a nonclustered index seek. A nonclustered index seek and key lookups
introduce seven times more reads to obtain the data.
The query selects four columns from the table:
CustomerId
,
LastName
,
FirstName
, and
Phone. LastName
and
FirstName
are key columns in the nonclustered index key.
CustomerId
is the clustered index key, which makes it the
row-id in the nonclustered index. The only column that is not present in the nonclustered index is
Phone
. You can
confirm it by looking at the output list in the
Key Lookup
operator properties in the execution plan.
Let's make our index covering by including the Phone column there and see how it affects the execution plan.
The code to achieve this is shown in Listing 4-2. Figure
4-3
shows the new execution plan.
Listing 4-2.
Creating a covering index and running the query a second time
create nonclustered index IDX_Customers_LastName_FirstName_PhoneIncluded
on dbo.Customers(LastName, FirstName)
include(Phone);
select CustomerId, LastName, FirstName, Phone
from dbo.Customers
where LastName = 'Smith';