Database Reference
In-Depth Information
Column-Based Storage and Batch-Mode Execution
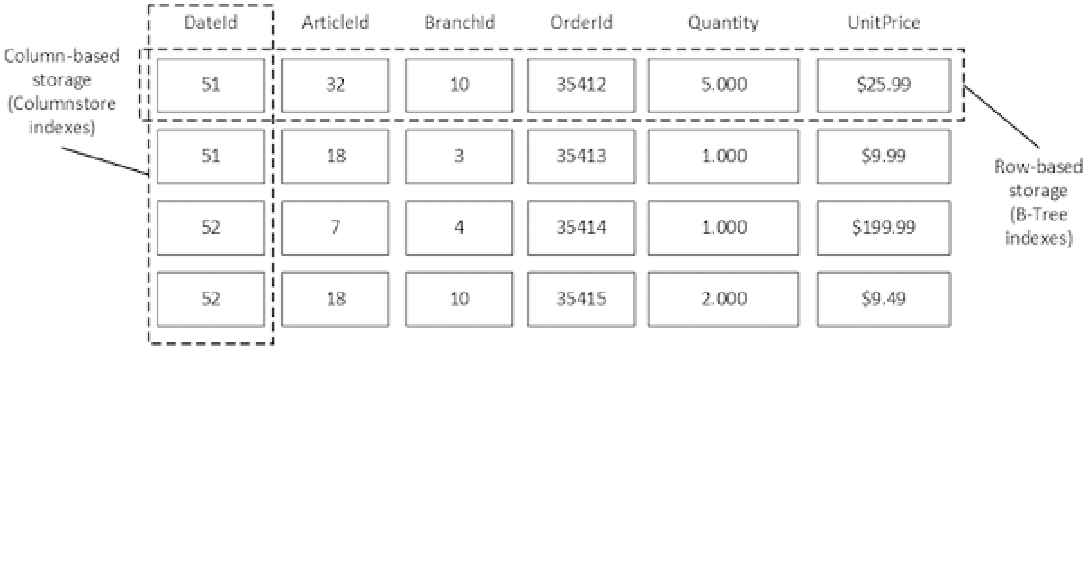
SQL Server addresses these problems with columnstore indexes and batch-mode execution. Columnstore indexes
store data on a per-column rather than on a per-row basis. Figure
34-3
illustrates this approach.
Figure 34-3.
Row-based and column-based storage
Data in columnstore indexes is heavily compressed using algorithms that provide significant space saving even
when compared to page compression. Moreover, SQL Server can skip columns that are not requested by a query, and
it does not load data from those columns into memory.
■
Note
We will compare the results of different compression methods in the next chapter.
The new data storage format of columnstore indexes allows SQL Server to implement a new batch-mode
execution model that significantly reduces the CPU load and execution time of Data Warehouse queries. In this
mode, SQL Server processes data in groups of rows, or batches, rather than one row at a time. The size of the batches
varies to fit into the CPU cache, which reduces the number of times that the CPU needs to request
external
data from
memory or other components. Moreover, the batch approach improves the performance of aggregations, which can
be calculated on a per-batch rather than on a per-row basis.
In contrast to row-based processing where data values are copied between operators, batch-mode processing
tries to minimize such copies by creating and maintaining a special bitmap that indicates if a row is still valid in
the batch.
To illustrate this approach, let's consider the following query:
Listing 34-2.
Sample query
select ArticleId, sum(Quantity)
from dbo.FactSales
where UnitPrice >=10.00
group by ArticleId
With regular, row-based processing, SQL Server scans a clustered index and applies a filter on every row. For
rows that have
UnitPrice >=10.00
, it passes another row of two columns (
ArticleId
and
Quantity
) to the
Aggregate
operator. Figure
34-4
shows this process.