Database Reference
In-Depth Information
create unique nonclustered index IDX_Data_DateModified_Id
on dbo.Data(DateModified, Id);
declare @StartDate datetime = '2014-01-01';
;with N1(C) as (select 0 UNION ALL select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,N6(C) as (select 0 from N5 as T1 cross join N2 as T2 cross join N1 as T3)
-- 524,288 rows
,IDs(ID) as (select row_number() over (order by (select NULL)) from N6)
insert into dbo.Data(ID, DateCreated, DateModified)
select ID, dateadd(second,35 * Id,@StartDate),
case
when ID % 10 = 0
then dateadd(second,
24 * 60 * 60 * (ID % 31) + 11200 + ID % 59 + 35 * ID,
@StartDate)
else dateadd(second,35 * ID,@StartDate)
end
from IDs;
Let's assume that we have a process that reads modified data from the table and exports it somewhere. While
there are a few different ways to implement such a task, perhaps the simplest method is to use a query, as shown in
Listing 15-30, with the
@DateModified
parameter representing the most recent
DateModified
value from the previous
record set read.
Listing 15-30.
Potential issues with data partitioning: Reading modified data
select top (@Top) Id, DateCreated, DateModified, PlaceHolder
from dbo.Data
where DateModified > @LastDateModified
order by DateModified, Id
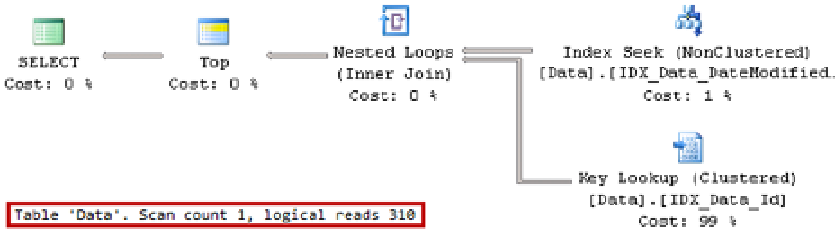
The execution plan of the query, which selects 100 rows, is shown in Figure
15-16
. The plan is very efficient, and
it utilizes a
Nonclustered Index Seek
with range scan. SQL Server finds the first row with a
DateModified
value that
exceeds
@LastDateModified
and then scans the index selecting the first 100 rows from there.
Figure 15-16.
Execution plan with non-partitioned table