Database Reference
In-Depth Information
A key XQuery concept is called
Atomization of nodes
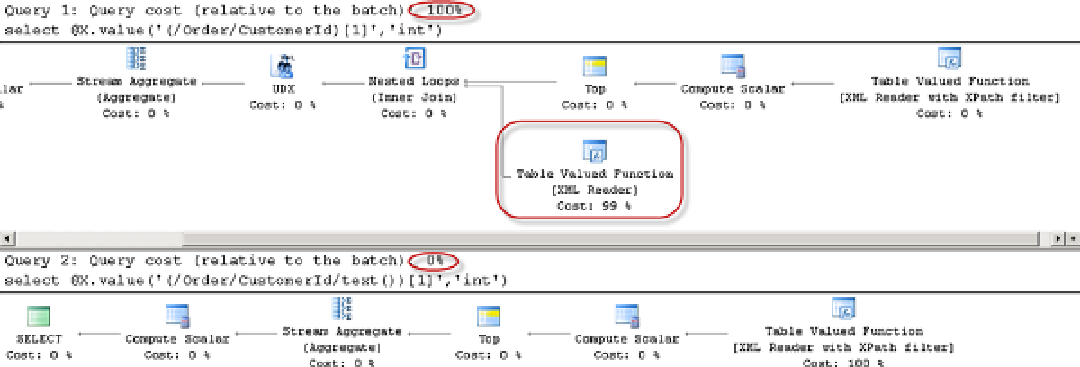
. When an XPath expression identifies an element in the
untyped XML, XQuery does not know if that element is the section or if it has any child nodes. As a result, it tries to
parse and concatenate the values from all XML child nodes from the section by adding another table-valued function
to the execution plan. Doing so could introduce a noticeable performance hit to the query. As the workaround,
use the XQuery function,
text()
, which returns the text representation of the element and eliminates the table-valued
function call.
Listing 11-8 shows an example of such behavior, and Figure
11-4
shows the execution plan of the two calls.
Listing 11-8.
Atomization of nodes overhead
declare
@X xml =
'<Order OrderId="42" OrderTotal="49.96">
<CustomerId>123</CustomerId>
<OrderNum>10025</OrderNum>
<OrderDate>2013-07-15T10:05:20</OrderDate>
<OrderLineItems>
<OrderLineItem>
<ArticleId>250</ArticleId>
<Quantity>3</Quantity>
<Price>9.99</Price>
</OrderLineItem>
<OrderLineItem>
<ArticleId>404</ArticleId>
<Quantity>1</Quantity>
<Price>19.99</Price>
</OrderLineItem>
</OrderLineItems>
</Order>'
select @X.value('(/Order/CustomerId)[1]','int')
select @X.value('(/Order/CustomerId/text())[1]','int')
Figure 11-4.
Atomization of nodes overhead