Image Processing Reference
In-Depth Information
C3
C3
C2
C1
C2
C1
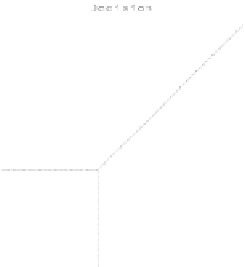
Figure 7.5.
Decision areas depending on the values of
m
1
(
C
2
)
and
m
2
(
C
3
)
by including
C
1
∪ C
3
for the second image (
m
2
(
C
3
)
an increasing mass on
which has to be smaller
1
− m
2
(
C
1
∪ C
3
)
than
). The dotted lines represent the previous limits
(see Figure 7.3)
The decision images in Figure 7.6 respectively show the results obtained for all
of the hypotheses except
D
and for all of the simple hypotheses only, first with
m
2
(
C
1
∪
C
3
).
This figure shows that the decision for all of the hypotheses includes all of the par-
tial volume areas between WM and the ALD in
C
1
∪
C
3
)=0and then with an increasing weight assigned to
m
2
(
C
1
∪
C
3
, and does not change if the
weights of
m
2
(
C
1
∪
C
3
) increase, which is another indication of the robustness with
respect to weighting. On the contrary, the decision images for the simple hypothe-
ses only show an increasing number of partial volume points that are included in the
ALD. This modeling makes it possible to imitate how a doctor would make his deci-
sion, based on his objective. In the image farther to the left, where the partial volume
is not taken into account, the area classified as ALD presents no ambiguity (and cor-
responds to “pure” ALD, without mixture), whereas on the image farther to the right,
all of the partial volume is included in the ALD (this corresponds to the actual seg-
mentation manually obtained by doctors) and the classified areas of the brain contain
no ambiguous parts.
We have tried here to illustrate a few of the characteristics of belief function the-
ory that can be used in image fusion for classification, segmentation or recognition
and that constitute advantages compared to the traditional probabilistic and Bayesian
methods. They reflect the high flexibility of possible models, taking into account at
the same time uncertainty and imprecision, partial or overall absence of knowledge,
the reliabilities of the sources, the ability of each source to provide reliable or unreli-
able information on each class,
a priori
information it may be impossible to represent
using probabilities, etc. The application presented here is a good illustration of these
various advantages. First of all, a model that is well suited to the problem is possible,























































































































Search WWH ::

Custom Search