Information Technology Reference
In-Depth Information
19
15
11
7
3
6
10
14
18
124589
12 13
16 17
a
1,1
x
1
a
1,2
x
2
a
1,3
x
3
a
1,
n
x
n
Figure 11.4
The graph of an inner product computation showing the order in which vertices
are pebbled. Input vertices are labeled with the entries in the matrix
A
and vector
x
that are
combined. Open vertices are product vertices; those above them are addition vertices.
3
such that
T
(
L
)
1
pebbling strategy
P
of
G
with
p
l
≥
1
for
2
≤
l
≤
L
−
1
and
p
1
≥
(
p
,
G
,
P
)=
2
n
2
−
n
, the minimum value, and the following bounds hold simultaneously:
T
(
L
)
l
n
2
+
2
n
2
n
2
+
n
≤
(
p
,
G
,
P
)
≤
Proof
The lower bound
T
(
L
)
l
L
, follows from Lemma
11.3.1
because there are
n
2
+
n
inputs and
n
outputs to the matrix-vector product. The upper
bounds derived below represent the number of operations performed by a pebbling strategy
that uses three level-1 pebbles and one pebble at each of the other levels.
Each of the
n
results of the matrix-vector product is computed as an inner product in
which successive products
a
i
,
j
x
j
are formed and added to a running sum, as suggested by
Fig.
11.4
.Eachofthe
n
2
entries of the matrix
A
(leaves of inner product trees) is used in
one inner product and is pebbled once at levels
L
,
L
(
p
,
G
,
P
)
≥
n
2
+
2
n
,1
≤
l
≤
1,
...
, 1 when needed. The
n
entries
in
x
are used in every inner product and are pebbled once at each level for each of the
n
inner products. First-level pebbles are placed on each vertex of each inner product tree in the
order suggested in Fig.
11.4
. After the root vertex of each tree is pebbled with a first-level
pebble, it is pebbled at levels 2,
...
,
L
.
It follows that one I/O operation is performed at each level on each vertex associated
with an entry in
A
and the outputs and that
n
I/O operations are performed at each level
on each vertex associated with an entry in
x
, for a total of 2
n
2
+
n
I/O operations at each
level. This pebbling strategy places a first-level pebble once on each interior vertex of each
of the
n
inner product trees. Such trees have 2
n
−
−
1 internal vertices. Thus, this strategy
takes 2
n
2
−
n
computation steps.
As the above results demonstrate, the matrix-vector product is an example of an
I/O-
bounded problem
, a problem for which the amount of I/O required at each level in the
memory hierarchy is comparable to the number of computation steps. Returning to the dis-
cussion in Section
11.1.2
, we see that as CPU speed increases with technological advances, a
balanced computer system can be constructed for this problem only if the I/O speed increases
proportionally to CPU speed.
The I/O-limited version of the MHG for the matrix-vector product is the same as the
standard version because only first-level pebbles are used on vertices that are neither input or
output vertices.





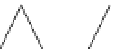









































Search WWH ::

Custom Search