Information Technology Reference
In-Depth Information
a
b
1st
Hermite b
a
sis functio
n
s
2nd
Hermite b
a
sis functi
o
ns
3
3
1
1
2
2
0.5
0.5
1
1
0
0
0
0
−1
−1
−0.5
−0.5
−2
−2
−3
−3
−1
−1
0
50
100
150
200
0
50
100
150
200
−10
−5
0
5
10
−10
−5
0
5
10
(a)
(b)
x
x
3rd Hermite basis functions
4th Hermite basis functions
3
3
1
1
2
2
0.5
0.5
1
1
0
0
0
0
−1
−1
−0.5
−0.5
−2
−2
−1
−1
−3
−3
0
50
100
150
200
0
50
100
150
200
−10
−5
0
5
10
−10
−5
0
5
10
x
x
(c)
(d)
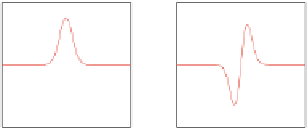
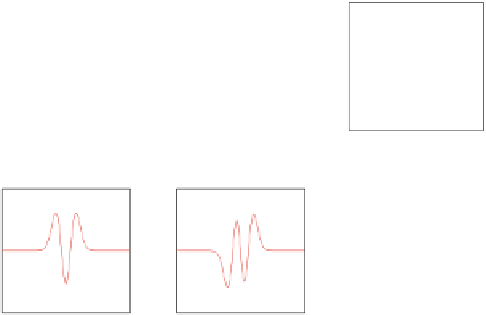
Fig. 12.4
(
a
) The first four modes of the Hermites series expansion (
b
) Fourier transform of the
basic mode of the Hermite expansion assuming the following variances: (
a
) 3
2
,(
b
) 5
2
,(
c
) 10
2
,
(
d
) 25
2
12.6
Multiscale Modelling of Dynamical System
The performance of neural networks that use the eigenstates of the quantum
harmonic oscillator as basis functions is compared to the performance of one hidden
layer FNN with sigmoidal basis functions (OHL-FNN), as well as to Radial Basis
Function (RBF) neural networks with Gaussian activation functions. It should be
noted that the sigmoidal basis functions .x/ D
1
1Cexp.x/
in OHL-FNN and
the Gaussian basis functions in RBF do not satisfy the property of orthogonality.
Unlike this, neural networks with Hermite basis functions use the orthogonal
eigenfunctions of the quantum harmonic oscillator which are given in Eq. (
12.10
).
In the sequel neural networks with Hermite basis functions, one hidden layer
FNN with sigmoidal basis functions and RBF neural networks with Gaussian
functions are used to approximate function y
k
D f.x
k
/ C
v
k
, where
v
k
is a noise
sequence, independent from x
k
's. The obtained results are depicted in Fig.
12.5
to Fig.
12.14
. The training pairs
were x
k
;y
k
. Root mean square error, defined as
RMSE
q
N
P
k1
.y
k
y
k
/
2
, gives a measure of the performance of the neural
D
networks.
In the case of RBF and of neural networks with Hermite basis functions, training
affects only the output weights, and can be performed with second order gradient
algorithms. However, since the speed of convergence is not the primary objective
of this study, the LMS (Least Mean Square) algorithm is sufficient for training. In
the case of the OHL-FNN with sigmoidal basis functions, training concerns weights
of both the hidden and output layer and is carried out using the back-propagation