Database Reference
In-Depth Information
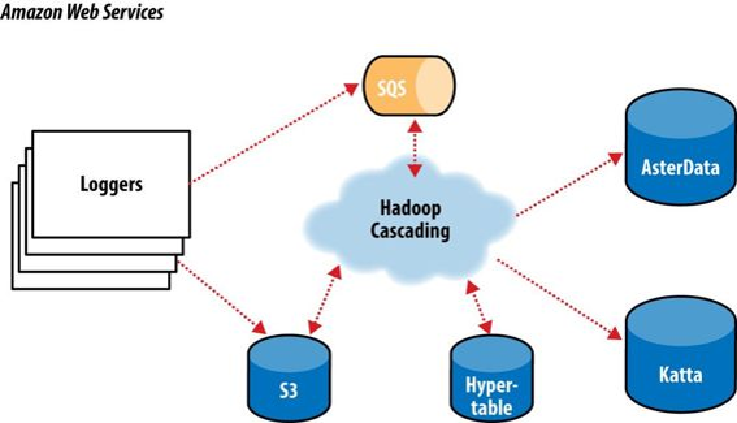
Figure 24-9. The ShareThis log processing pipeline
With Hadoop as the frontend, all the event logs can be parsed, filtered, cleaned, and or-
ganized by a set of rules before ever being loaded into the AsterData cluster or used by
any other component. AsterData is a clustered data warehouse that can support large data-
sets and that allows for complex ad hoc queries using a standard SQL syntax. ShareThis
chose to clean and prepare the incoming datasets on the Hadoop cluster and then to load
that data into the AsterData cluster for ad hoc analysis and reporting. Though that process
would have been possible with AsterData, it made a lot of sense to use Hadoop as the first
stage in the processing pipeline to offset load on the main data warehouse.
Cascading was chosen as the primary data processing API to simplify the development
process, codify how data is coordinated between architectural components, and provide
the developer-facing interface to those components. This represents a departure from more
“traditional” Hadoop use cases, which essentially just query stored data. Cascading and
Hadoop together provide a better and simpler structure for the complete solution, end to
end, and thus provide more value to the users.
For the developers, Cascading made it easy to start with a simple unit test (created by sub-
classing
cascading.ClusterTestCase
) that did simple text parsing and then to
layer in more processing rules while keeping the application logically organized for main-
tenance. Cascading aided this organization in a couple of ways. First, standalone opera-