Database Reference
In-Depth Information
Fields, Tuples, and Pipes
The MapReduce model uses keys and values to link input data to the map function, the
map function to the reduce function, and the reduce function to the output data.
But as we know, real-world Hadoop applications usually consist of more than one MapRe-
duce job chained together. Consider the canonical word count example implemented in
MapReduce. If you needed to sort the numeric counts in descending order, which is not an
unlikely requirement, it would need to be done in a second MapReduce job.
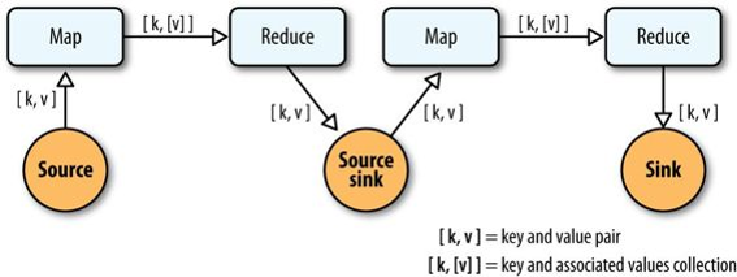
So, in the abstract, keys and values not only bind map to reduce, but reduce to the next
map, and then to the next reduce, and so on (
Figure 24-1
). That is, key-value pairs are
sourced from input files and stream through chains of map and reduce operations, and fi-
nally rest in an output file. When you implement enough of these chained MapReduce ap-
plications, you start to see a well-defined set of key-value manipulations used over and
over again to modify the key-value data stream.
Figure 24-1. Counting and sorting in MapReduce
Cascading simplifies this by abstracting away keys and values and replacing them with
tuples that have corresponding field names, similar in concept to tables and column names
in a relational database. During processing, streams of these fields and tuples are then ma-
nipulated as they pass through user-defined operations linked together by pipes (
Fig-
ure 24-2
).