Database Reference
In-Depth Information
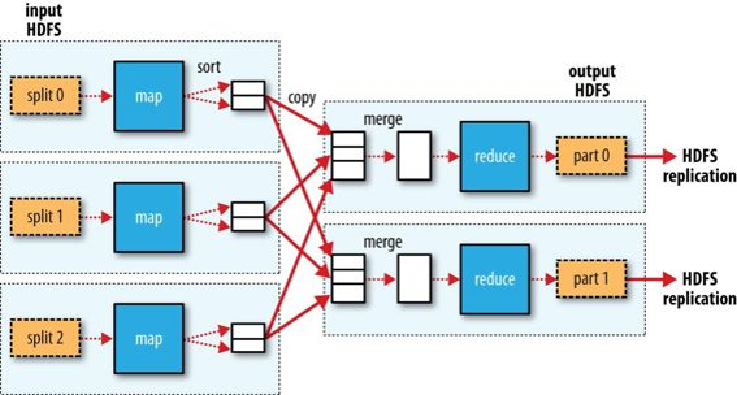
Figure 2-4. MapReduce data flow with multiple reduce tasks
Finally, it's also possible to have zero reduce tasks. This can be appropriate when you
don't need the shuffle because the processing can be carried out entirely in parallel (a few
examples are discussed in
NLineInputFormat
)
. In this case, the only off-node data transfer
is when the map tasks write to HDFS (see
Figure 2-5
).
Combiner Functions
Many MapReduce jobs are limited by the bandwidth available on the cluster, so it pays to
minimize the data transferred between map and reduce tasks. Hadoop allows the user to
specify a
combiner function
to be run on the map output, and the combiner function's out-
put forms the input to the reduce function. Because the combiner function is an optimiza-
tion, Hadoop does not provide a guarantee of how many times it will call it for a particular
map output record, if at all. In other words, calling the combiner function zero, one, or
many times should produce the same output from the reducer.