Database Reference
In-Depth Information
Parquet File Format
A Parquet file consists of a header followed by one or more blocks, terminated by a footer.
The header contains only a 4-byte magic number,
PAR1
, that identifies the file as being in
Parquet format, and all the file metadata is stored in the footer. The footer's metadata in-
cludes the format version, the schema, any extra key-value pairs, and metadata for every
block in the file. The final two fields in the footer are a 4-byte field encoding the length of
the footer metadata, and the magic number again (
PAR1
).
The consequence of storing the metadata in the footer is that reading a Parquet file requires
an initial seek to the end of the file (minus 8 bytes) to read the footer metadata length, then
a second seek backward by that length to read the footer metadata. Unlike sequence files
and Avro datafiles, where the metadata is stored in the header and sync markers are used to
separate blocks, Parquet files don't need sync markers since the block boundaries are
stored in the footer metadata. (This is possible because the metadata is written after all the
blocks have been written, so the writer can retain the block boundary positions in memory
until the file is closed.) Therefore, Parquet files are splittable, since the blocks can be loc-
ated after reading the footer and can then be processed in parallel (by MapReduce, for ex-
ample).
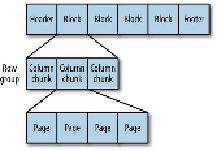
Each block in a Parquet file stores a
row group
, which is made up of
column chunks
con-
taining the column data for those rows. The data for each column chunk is written in
pages
;
this is illustrated in
Figure 13-1
.
Figure 13-1. The internal structure of a Parquet file
Each page contains values from the same column, making a page a very good candidate for
compression since the values are likely to be similar. The first level of compression is
achieved through how the values are encoded. The simplest encoding is plain encoding,
where values are written in full (e.g., an
int32
is written using a 4-byte little-endian rep-
resentation), but this doesn't afford any compression in itself.
Parquet also uses more compact encodings, including delta encoding (the difference
between values is stored), run-length encoding (sequences of identical values are encoded