Database Reference
In-Depth Information
which is then used to construct partitions. Luckily, we don't have to write the code to do
this ourselves, as Hadoop comes with a selection of samplers.
The
InputSampler
class defines a nested
Sampler
interface whose implementations
return a sample of keys given an
InputFormat
and
Job
:
public interface
Sampler
<
K
,
V
> {
K
[]
getSample
(
InputFormat
<
K
,
V
>
inf
,
Job job
)
throws
IOException
,
InterruptedException
;
}
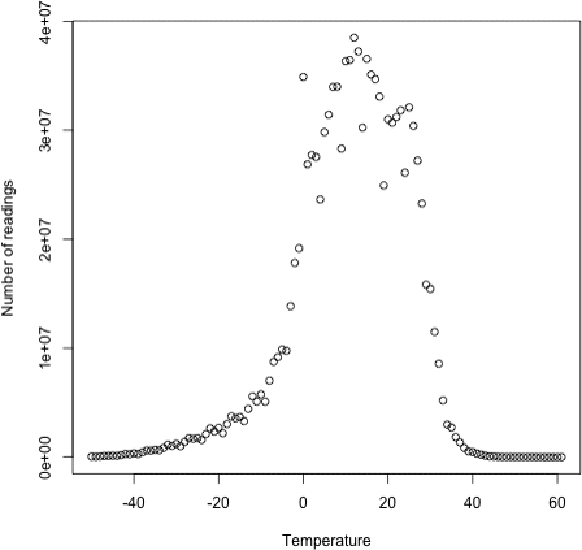
Figure 9-1. Temperature distribution for the weather dataset
This interface usually is not called directly by clients. Instead, the
writeParti-
tionFile()
static method on
InputSampler
is used, which creates a sequence file
to store the keys that define the partitions: