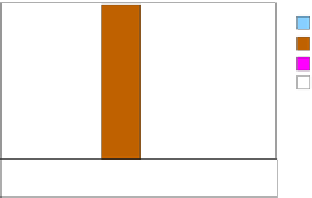Information Technology Reference
In-Depth Information
A11
A21
A31
Padding
Fig. 5.
Modified storage scheme for symmetric band matrices and how it is accessed
in the inner loop from sbmm
BLK
Figure 5 shows the modified storage scheme and how it is accessed during an
inner loop iteration in sbmm
BLK
. The strictly lower triangular part of
A
31
is
now conveniently placed in the added rows. Consequently, blocks
A
21
and
A
31
can be merged, and so can the operations they are involved in. Thus, the updates
performed at each step of the inner loop can be reformulated as:
E
1
:=
E
1
+
A
11
·
D
1
,
E
1
:=
E
1
+
A
21
A
31
·
D
1
E
2
E
3
:=
E
2
E
3
+
A
21
A
31
D
2
D
3
.
·
This approach presents two main advantages:
-
The number of invocations to CUBLAS kernels is reduced from 8 to 3 per
step and, consequently, the overhead introduced by the kernels invocations
is also reduced.
-
It eliminates the invocations to kernels with a moderate to low cost, which
can not exploit the massively parallel architecture of the GPU. Concretely,
the operations that dissapear involve triangular matrices and present load-
balancing problems.
There are also some drawbacks related to this implementation. First of all, the
memory requirements are enlarged. In addition, the number of arithmetic opera-
tions is also increased, as it operates with the null elements in
A
11
and
A
31
.
4.3
Implementation
sbmv
ms
Additionally, we implemented a symmetric banded matrix-vector product vari-
ant based on the modified storage scheme. Due to the different storage scheme,
this variant may be slightly faster than the implementation from CUBLAS.The
overhead introduced by transforming
A
to the modified storage can be relatively
high, in principle higher than the gain that sbmv
ms
introduces with respect to