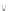Information Technology Reference
In-Depth Information
c
c
c
k+1
b
readed
.
updated
k+1
=+
b
C1
C1
C2
A11
B1
k+1
C2
A21
A
30
C3
C3
A31
Fig. 4.
Elements read and updated during a step of the inner loop of the sbmm
BLK
algorithm
where
A
is an upper or lower triangular matrix and
op
(
A
) denotes
A
or
A
T
hereafter. In contrast, the updates of
C
1
and
C
3
require an operation of the type
C
=
C
+
ʱop
(
A
)
B,
(4)
To overcome this problem, routine sbmm
blk
performs the following sequence of
operations in order to update
C
1
:
(trmm)
W
=
A
31
B
1
,
(geam)
C
1
=
C
1
+
W.
(Next to each operation, we indicate the CUBLAS kernel that implements it.)
Theupdateof
C
3
is analogous. This procedure requires an auxiliary workspace
(
W
R
b×c
).
High performance can be expected of this implementation due to the use of
tuned CUBLAS routines.
∈
4.2
Implementation
sbmm
blk
+
ms
The sbmm
blk
implementation presents some drawbacks that reduce its perfor-
mance. In particular, it requires up to 6 operations per iteration. Besides, two
of the operations involve a triangular matrix and are computed in two steps
(as discussed in the previous subsection). Thus, up to 8 kernels are invoked at
each iteration and some of them require a low computational effort (as do the
two invocations to geam). The sbmm
blk
+
ms
implementation aims to reduce the
number of routine invocations, specifically, by removing those with a lower com-
putational cost. To make this possible, we perform some changes in the matrix
storage. Assume
A
presents a symmetric band structure and its lower part is
stored following the BLAS specific format. Then, in order to accelerate algo-
rithm sbmm
BLK
we add
b
additional rows to the bottom of
A
. Correspondingly,
when the upper part of
A
is stored, then the new rows should be added at the
top of
A
. Additionally, in a GPU environment, we suggest that this number is
chosen to enable a coalesced access to the elements of
A
.