Information Technology Reference
In-Depth Information
Fig. 4.
MBSPTree structure generated by MBSPDiscover
The Corebenchmark Module.
We explain in detail the implementation of
the
coreBenchmark
module for computing the parameters
g
i
and
L
i
.
The
coreBenchmark
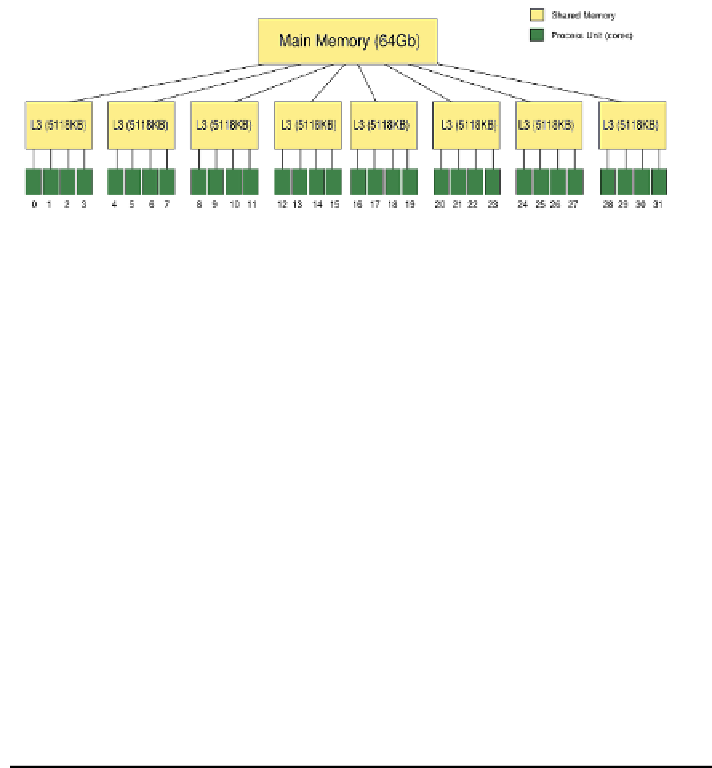
function is shown in Algorithm 1.2. It receives as param-
eters the information of the corresponding level based in the MultiBSP Model,
and data for anity like the core indexes and the size of cache memory, which
arestoredinthe
MBSPTree
structure. At the beginning (line 2),
coreBenchmark
uses the
setPinning
function from the
affinity
module.
setPinning
binds the
threads spawned by the
begin
function (line 3) to the cores corresponding to
the current level. The function spawns one thread per core in that level and cal-
culates the computing rate of the MultiBSP component using
computingRate
function (line 4). Each level has a set of cores sharing one memory, then for
benchmarking a level, only those cores are considered.
The
computingRate
function measures the time required to perform
2
×
n
×
DAXPY
operations. The
DAXPY
routine performs the vector operation
y
=
ʱ
∗
x
+
y
, adding a multiple of a double precision vector to another double preci-
sion vector.
DAXPY
is a standard BLAS1 operation
3
for estimating the platform
eciency when performing memory-intensive floating point operations.
1
function coreBenchmark(level) {
2
setPinning(level.cores_indexes)
3
4
begin(level.cores)
5
rate = computingRate(level)
6
sync()
7
8
for
(h=0; h<HMAX; h++) {
9
10
initCommunicationPattern(h)
11
sync()
12
13
t0 = time()
14
15
for
(i=0; i<NITERS; i++) {
16
communication()
17
sync()
18
}
19
20
t = time() - t0
21