Information Technology Reference
In-Depth Information
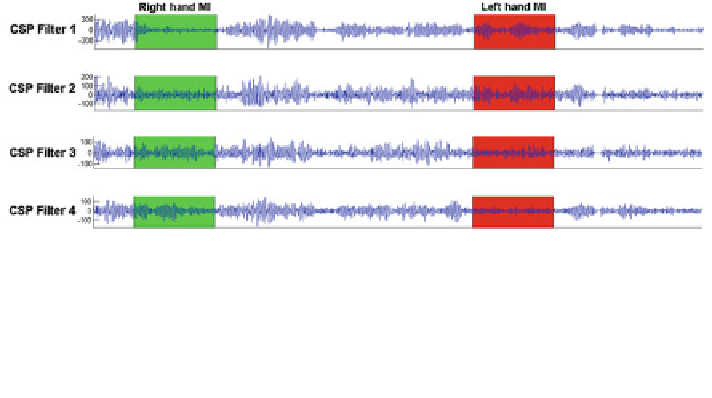
Fig. 7.5
EEG signals spatially filtered using the CSP algorithm. The first two spatial filters (
top
filters
) are those maximizing the variance of signals from class
“
left hand motor imagery
”
while
minimizing that of class
They correspond to the largest eigenvalues of
the GEVD. The last two filters (
bottom
filters
) are the opposite, they maximize the variance of
class
“
right hand motor imagery.
”
(they
correspond to the lowest eigenvalues of the GEVD). This can be clearly seen during the periods of
right
or
left hand
motor imagery, in
light
and
dark gray,
respectively
“
right hand motor imagery
”
while minimizing that of class
“
left hand motor imagery
”
Nevertheless, despite all these advantages, CSP is not exempt from limitations
and is still not the ultimate signal-processing tool for EEG-based BCI. In particular,
CSP has been shown to be non-robust to noise, to non-stationarities and prone to
over
tting (i.e., it may not generalize well to new data) when little training data is
available (Grosse-Wentrup and Buss
2008
; Grosse-Wentrup et al.
2009
; Reuderink
and Poel
2008
). Finally, despite its versatility, CSP only identi
es the relevant
spatial information but not the spectral one. Fortunately, there are ways to make
CSP robust and stable with limited training data and with noisy training data. An
idea is to integrate prior knowledge into the CSP optimization algorithm. Such
knowledge could represent any information we have about what should be a good
spatial
filter for instance. This can be neurophysiological prior, data (EEG signals)
or meta-data (e.g., good channels) from other subjects, etc. This knowledge is used
to guide and constraint the CSP optimization algorithm toward good solutions even
with noise, limited data, and non-stationarities (Lotte and Guan
2011
). Formally,
this knowledge is represented in a regularization framework that penalizes unlikely
solutions (i.e., spatial
filters) that do not satisfy this knowledge therefore enforcing
it. Similarly, prior knowledge can be used to stabilize statistical estimates (here,
covariance matrices) used to optimize the CSP algorithm. Indeed, estimating
covariance matrices from few training data usually leads to poor estimates (Ledoit
and Wolf
2004
).
Formally, a regularized CSP (RCSP) can be obtained by maximizing both
Eqs.
7.4
and
7.5
:
wC
1
w
T
wC
2
w
T
þ k
P
ð
w
Þ
J
RCSP1
ð
w
Þ¼
ð
7
:
4
Þ