Information Technology Reference
In-Depth Information
c
M
i
F
c
F
i
c
M
o
i
M
o
F
o
Fig. 13.2
Pose estimation using VVS
The matrix
c
M
o
can be estimated by minimizing the error module in image
s
(
c
M
o
)
s
∗
e
=
−
(13.6)
where
s
∗
is the value of a set of visual features computed in the image acquired in
the camera unknown position and
s
(
c
M
o
) is the value of the same set of features
computed from the object model, the transformation
c
M
o
, and the camera model.
VVS consists in moving a virtual camera from a known initial pose
i
M
o
(referenced
by the frame
F
i
on Figure 13.2) to the final unknown pose (referenced by the frame
F
c
on Figure 13.2) where
e
is minimized. In fact, the main difference between VS
and VVS is that the visual features at each iteration are computed in VVS, while
they are extracted from acquired images in VS. However, the displacement of the
camera (real or virtual) is computed using the same control law (13.4).
13.3.2
Moments from the Projection of Points onto the Surface of
Unit Sphere
In the following, the definition of the 3D moments computed from a discrete set of
N
points is firstly recalled. Then, the interaction matrix related to these moments
computed from the point projection onto the unit sphere is given.
13.3.2.1
Definitions
The 3D moment of order
i
+
j
+
k
computed from a discrete set of
N
points are
defined by the classical equation
N
h
=1
x
s
h
y
s
h
z
s
h
m
i
,
j
,
k
=
(13.7)



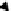


















Search WWH ::

Custom Search