Java Reference
In-Depth Information
Local and Remote Parallelization
As discussed earlier, the scale of batch jobs and the need to be able to scale them is vital to any
enterprise batch solution. Spring Batch provides the ability to approach this in a number of different
ways. From a simple thread-based implementation, where each commit interval is processed in its own
thread of a thread pool; to running full steps in parallel; to configuring a grid of workers that are fed units
of work from a remote master via partitioning; Spring Batch provides a collection of different options,
including parallel chunk/step processing, remote chunk processing, and partitioning.
Standardizing I/O
Reading in from flat files with complex formats, XML files (XML is streamed, never loaded as a whole), or
even a database, or writing to files or XML, can be done with only XML configuration. The ability to
abstract things like file and database input and output from your code is an attribute of the
maintainability of jobs written in Spring Batch.
The Spring Batch Admin Project
Writing your own batch-processing framework doesn't just mean having to redevelop the performance,
scalability, and reliability features you get out of the box with Spring Batch. You also need to develop
some form of administration toolset to do things like start and stop processes and view the statistics of
previous job runs. However, if you use Spring Batch, it includes all that functionality as well as a newer
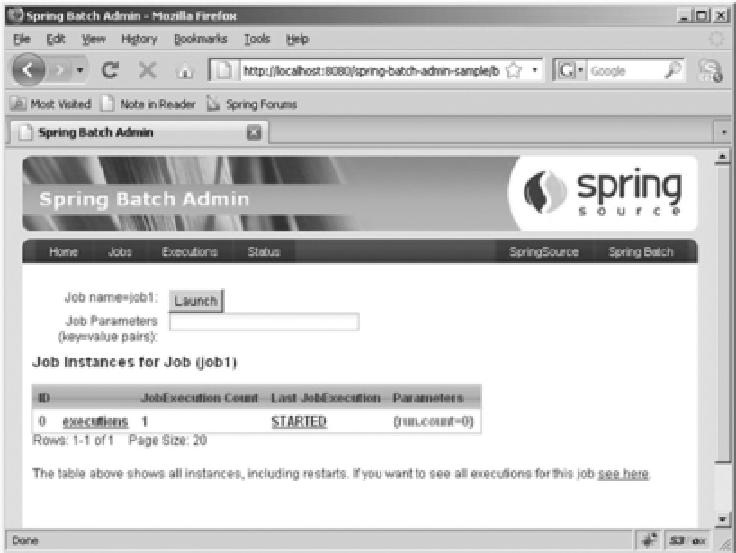
addition: the Spring Batch Admin project. The Spring Batch Admin project provides a web-based control
center that provides controls for your batch process (like launching a job, as shown in Figure 1-4) as well
as the ability to monitor the performance your process over time.
Figure 1-4.
The Spring Batch Admin project user interface