Information Technology Reference
In-Depth Information
Intron
Exon
A. DNA
Transcription
B. RNA
Translation
amino acids
C. Polypeptide
D. Protein
E. Metabolites
Fig. 3.2
Molecular biology refresher. (
A
-
C
) The central dogma of biology: DNA exists in the cell
nucleus. Through a process known as transcription, the DNA is “read” and a matching strand of
RNA is created. After further processing of this messenger RNA (
mRNA
), the specifi c sequence is
“translated” into a corresponding sequence of amino acids, forming a polypeptide chain. (
D
) This
chain folds in a highly specifi c manner to form a three-dimensional protein structure. This 3D
structure, and consequently the functionality of the protein, may be affected by post-translational
modifi cations, e.g. the addition of a phosphate group (PO
4
) (
E
). Proteins are broken down into
metabolites to be eliminated from the cell
One's DNA sequence, or genome, is generally the same across every cell in the
body, while changes in the expression levels of genes, and the quantity and state of
gene products (i.e. proteins) determine both the cell type and the biological state of
the cell. The ability to measure which genes and gene products are active in different
tissues gives critical clues regarding the underlying mechanisms of biological pro-
cesses and how these processes can be disrupted in disease.
3.2.2
The “Omics” Revolution
The amount that is known about the human genome, and the tools at our disposal to
learn more have expanded signifi cantly since most of today's adults last took a
course in biology. The mid-1990s saw the advent of DNA microarray technology,
which could be used to quantitate the expression of tens of thousands of genes in a
single assay. In 2001, a complete draft of the human genome sequence was
announced by two different competing groups. The public effort, led by the NIH,
was carried out with the intention to share all data from the start [
1
]. Celera































































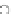



















Search WWH ::

Custom Search