Information Technology Reference
In-Depth Information
Sources of Data
Sources of Knowledge
and Expertise
EHR/PHR-derived
Phenotype
Domain-
Knowledge
Bio-molecular
Instrumentation
Prior Study
Results
Physical
or Virtual
Integrated
Data Repository
Investigator(s)
Heuristics
Research-specific
Data Capture
Instruments
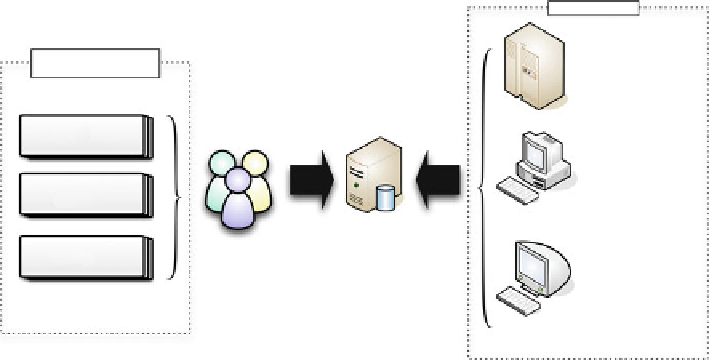
Fig. 8.1
Overview of traditional, investigator-driven approach to asking and answering questions
regarding complex and large scale data sets. In this model, the investigator (or research team)
serves as the primary integration of various sources of knowledge and expertise, formulating and
asking questions concerning available data using a combination of their domain knowledge, expe-
riential knowledge from prior studies, and heuristics that they may have formulated relative to an
application domain
the clinical research environment and clinical or public health practice [
2
]. For both
of these categories of challenges, the methods required to address them are extremely
reliant on the provision of tools and methods that can facilitate the collection, formal-
ization, analysis and dissemination of large-scale and integrative data sets [
3
]. The
potential impact of informatics-based approaches in terms of addressing such infor-
mation needs has been well established; yet those same tools and methods remain
largely under-utilized by the research and practice communities [
4
-
12
].
Within this broad context, one major area of concern is the way in which we
formulate and test hypotheses relative to “big” biomedical data
. This concern is
amplifi ed by the fact that the volume, velocity and variability of biomedical data
continue to expand at a rapid rate. This growth is in large part a function of the
proliferation of computerized sources of biomedical data, such as Electronic Health
Records (EHRs), Personal Health Records (PHRs), Clinical Trial or Research
Management Systems (CTMS/CRMS), high-throughput bio-molecular instrumen-
tation, and ubiquitous sensor technologies. While computational methods continue
to be devised and applied to support or enable the capture, storage and transaction
of these data sets, there has not been a corresponding focus on improvements in the
ways in which we ask and answer important questions utilizing this data. In fact,
the traditional, reductionist approach to intuitive hypothesis generation based on the
expertise or insights of an individual or small number of investigators remains the
norm (Fig.
8.1
). However, this approach is highly linear, and limited by the cogni-
tive capacities of such investigators or teams, leading to an underutilization of avail-
able and costly to assemble data sets.
In effect, we continue to create and maintain bigger and more complex data sets
at great expense, while we ask and answer small numbers of questions regarding the
Search WWH ::

Custom Search