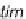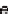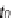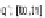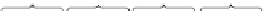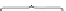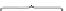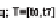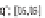Information Technology Reference
In-Depth Information
Individual historical facts may not be much meaningful to users, however, assembling
or relating them with other evidence should make the returned information more
useful and interesting.
Knowledge is basically the information about “relations”. Document archives by
grouping the artifacts and enabling their automatic access provide a powerful
framework for knowledge acquisition in which topical and chronological order allows
inferring higher-level relations (e.g., changes in ideas, evolution of ideas or topics,
event co-occurrence and periodicity, etc.). For example, even if a given idea is
known, its evolution over time and relation to other ideas provides new kind of
knowledge.
In general, recent technological advancements in computing offer possibility of
semi-automatic or automatic interaction with historical document collections and for
producing interesting knowledge. Historical document archives should be then
considered more as sources of topically and chronologically arranged data to be
mined for useful knowledge. One way to infer knowledge is to use only the data in the
collection itself while another is to measure relations (e.g., correlation) to other
external data sources.
In reality, often, it is impossible to scan the entire collections for knowledge
extraction in document archives, and the only allowable access way is through a
search interface. This is usually due to their huge size, proprietary character or access
restrictions. Effective mining applications should thus harness the provided searching
facility as a means of knowledge acquisition. Already, effective ways for mining
search engine indices through their search interfaces have been proposed in web
mining area [4,5]. Bollegala et al. [4] measured inter-term similarity by analyzing web
search results. Cilibrasi and Vitányi [5] proposed Google Normalized Distance based
on web count values in order to use it for such tasks as hierarchical clustering,
classification or language translation.
Figure 1 portrays a schematic way to sample historical document collection via its
search interface, for example, to obtain longitudinal statistics such as the occurrence
of particular feature over time. First, an application issues query to an online news
archive. It is there transformed into a series of sub-queries spanning over a predefined
time period
T=[t
beg
,t
end
]
, each with a temporal constrain. The initial time period
T
is
partitioned into
R
number of continuous and non-overlapping time units, which serve
as temporal constraints for the sub-queries. The number of partitions (i.e. granularity)
Fig. 1.
Simple model of data collection for longitudinal knowledge acquisition from historical
archives by querying search engine interfaces