Database Reference
In-Depth Information
Let's take an example. Let's say you have five nodes containing a row key K (that is, RF
equals five), your read
ConsistencyLevel
is three; then the closest of the five nodes
will be asked for the data and the second and third closest nodes will be asked to return
the digest. If there is a difference in the digests, full data is pulled from the conflicting
node and the latest of the three will be sent. These replicas will be updated to have the
latest data. We still have two nodes left to be queried. If read repairs are not enabled, they
will not be touched for this request. Otherwise, these two will be asked to compute the di-
gest. Depending on the
read_repair_chance
setting, the request to the last two
nodes is done in the background, after returning the result. This updates all the nodes with
the most recent value, making all replicas consistent.
Let's see what goes on within a node. Take a simple case of a read request looking for a
single column within a single row. First, the attempt is made to read from MemTable,
which is rapid fast, and since there exists only one copy of data, this is the fastest retriev-
al. If all required data is not found there, Cassandra looks into SSTable. Now, remember
from our earlier discussion that we flush MemTables to disk as SSTables and later when
the compaction mechanism wakes up, it merges those SSTables. So, our data can be in
multiple SSTables.
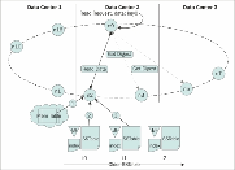
The following figure represents a simplified representation of the read mechanism. The
bottom of the figure shows processing on the read node. The numbers in circles show the
order of the event. BF stands for bloom filter.
Each SSTable is associated with its bloom filter built on the row keys in the SSTable.
Bloom filters are kept in the memory and used to detect if an SSTable may contain (false
positive) the row data. Now, we have the SSTables that may contain the row key. The
SSTables get sorted in reverse chronological order (latest first).