Database Reference
In-Depth Information
Setting up local Hadoop
This section will discuss how to set up Hadoop 2.6.0 (should be valid for all 2.x versions)
on your local machine. At the time of writing this, Hadoop has transitioned from version 1
to version 2. Version 2.x is mature now and has disruptive changes. It is presumably better
than version 1. HDFS is federated in the new version. The Apache documentation says that
this version scales NameNode service horizontally using multiple independent
NameNodes. This should ideally avoid the single point of failure that NameNodes faced in
the previous version. The other major improvement is in the new MapReduce frameworks,
for example, MRNextGen, MRv2, and
Yet Another Resource Negotiator
(
YARN
). More
about the new version can be learned on the Apache website (
http://hadoop.apache.org/
docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
)
. Here are the steps to get Hadoop
Version 2.x to work on a Linux machine. To keep things generic, I have used the dow-
loaded zipped file to install the Hadoop. One can use a binary package for a specific plat-
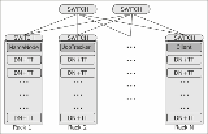
form without much of a change in the instructions. The following figure shows Hadoop in-
frastructure. Heavy-duty master nodes are at the top of the rack servers. Each rack has a
rack switch. Slaves run DataNode and TaskTracker services. Racks are connected through
10GE switches. Note that not all racks will have a master server:
Make sure you can add SSH to your local host using a key-based password-less login. If
you can't do this, generate and set a key pair as described in the following commands:
# Generate key pair
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /home/ec2-user/.ssh/
id_dsa.
Your public key has been saved in /home/ec2-user/.ssh/
id_dsa.pub.
The key fingerprint is: