Database Reference
In-Depth Information
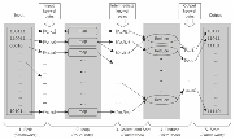
move punctuation, split the words by a white space, iterate in this split array of words, for-
ward key as an individual word, and set the value as one. These make the intermediate
key-value pair, as indicated in the following figure:
Hadoop MapReduce framework in action (simplified)
These results are sorted by the key and forwarded to the Reducer interface that you
provided. Incoming tuples have the same key, and reducers can use this property in their
logic. Understanding this sentence is important to a beginner. What it means is that you
can just iterate in the incoming iterator and do things such as group or count—basically
reduce or fold the map by a key.
The reduced values are then stored in a place of your choice, which can be HDFS,
RDBMS, Cassandra, or one of the many other storage options.
There are two main processes that you should know about in context of Hadoop MapRe-
duce, which we will talk about in a bit.
JobTracker
Similar to NameNode, JobTracker is a master process that governs the execution of work-
er threads such as TaskTracker. Like any master-slave architecture, JobTracker is a single
point of failure. Therefore, it is advisable to have robust hardware and redundancy built
into the machine that has JobTracker running.
JobTracker's responsibility includes estimating the number of Mapper tasks from the input
split, for example, file splits from HDFS via
InputFormat
. It uses already configured
values as numbers of Reducer tasks. A client application can use JobClient to submit jobs
to JobTracker and inquire the status of a job.