Database Reference
In-Depth Information
There are two ways to avoid this imbalance in key distribution:
•
Offsetting tokens slightly
: This mechanism is the same as the one that we just
discussed. The algorithm for offsetting tokens is as follows:
1. Calculate the token range as if each data center is a ring.
2. Offset the values that are duplicated by a small amount, say by 1 or 10 or
100.
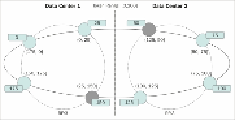
Here is an example. Let's say we have a cluster spanning three data cen-
ters.
Data-center 1
and
Data-center 2
have three nodes each,
and
Data-center 3
has two nodes. We use
RandomPartitioner
.
Here is the split (the final value is used, the duplicates are offset):
# Duplicates are offset, final are assigned
Data-center 1:node1: 0 (final)
node2: 56713727820156410577229101238628035242
(final)
node3: 113427455640312821154458202477256070485
(final)
Data-center 2:node1: 0 (duplicate, offset to
avoid collision) 1 (final)
node2: 56713727820156410577229101238628035242
(duplicate, offset)
56713727820156410577229101238628035243 (final)
node3: 113427455640312821154458202477256070485
(duplicate, offset)
113427455640312821154458202477256070486 (final)