Information Technology Reference
In-Depth Information
Table 2.10
The clustering results of the car data set by Algorithm-IFSC in different
λ
levels
λ
level
Clustering results
0
≤
λ
≤
0
.
709
{
y
1
,
y
2
,
y
3
,
y
4
,
y
5
,
y
6
,
y
7
,
y
8
,
y
9
,
y
10
}
0
.
709
<λ
≤
0
.
771
{
y
1
,
y
6
}
,
{
y
2
,
y
3
,
y
4
,
y
5
,
y
7
,
y
8
,
y
9
,
y
10
}
0
.
771
<λ
≤
0
.
811
{
y
1
,
y
6
}
,
{
y
2
}
,
{
y
3
,
y
5
,
y
7
,
y
10
}
,
{
y
8
}
,
{
y
4
,
y
9
}
0
.
811
<λ
≤
0
.
861
{
y
1
,
y
6
}
,
{
y
2
}
,
{
y
3
,
y
7
}
,
{
y
8
}
,
{
y
4
,
y
9
}
,
{
y
5
,
y
10
}
0
.
861
<λ
≤
0
.
889
{
y
1
,
y
6
}
,
{
y
2
}
,
{
y
3
,
y
7
}
,
{
y
4
,
y
9
}
,
{
y
5
}
,
{
y
8
}
,
{
y
10
}
0
.
889
<λ
≤
0
.
913
{
y
1
,
y
6
}
,
{
y
2
,
y
3
,
y
7
}
,
{
y
4
,
y
9
}
,
{
y
5
}
,
{
y
8
}
,
{
y
10
}
0
.
913
<λ
≤
0
.
919
{
y
1
,
y
6
}
,
{
y
2
}
,
{
y
3
,
y
7
}
,
{
y
4
,
y
9
}
,
{
y
5
}
,
{
y
8
}
,
{
y
10
}
0
.
919
<λ
≤
0
.
937
{
y
1
}
,
{
y
2
}
,
{
y
5
}
,
{
y
6
}
,
{
y
3
,
y
7
}
,
{
y
4
,
y
9
}
,
{
y
8
}
,
{
y
10
}
0
.
937
<λ
≤
0
.
968
{
y
1
}
,
{
y
2
}
,
{
y
3
}
,
{
y
5
}
,
{
y
6
}
,
{
y
7
}
,
{
y
8
}
,
{
y
4
,
y
9
}
,
{
y
10
}
0
.
968
<λ
≤
1
{
y
1
}
,
{
y
2
}
,
{
y
3
}
,
{
y
4
}
,
{
y
5
}
,
{
y
6
}
,
{
y
7
}
,
{
y
8
}
,
{
y
9
}
,
{
y
10
}
Note
:(1)
λ
is used to cut the association matrix of Algorithm 2.2 to produce the clusters
several clusters. For instance, a VOLVO car is often famous for its safety equipment.
On the other hand, it is also a luxury car with a relatively high price. So a VOLVO
car can naturally be grouped into the safe car cluster and the luxury car cluster
simultaneously. Viewing from this angle, Algorithm 2.7 indeed can generate more
valuable information than Algorithm 2.2.
Furthermore, compared with Algorithm 2.2, Algorithm 2.7 has lower compu-
tational complexity. Roughly speaking, the storage required by Algorithm 2.7 is
O
, where
p
is the number of samples in the data,
n
is the number of
IFSs in a sample, and
c
is the number of clusters. The time requirement for Algorithm
2.7 is
O
(
p
(
n
+
c
)
+
cn
)
, where
I
is the maximum number of iterations preset for the optimal
value searching process. Since in most cases
n
and
c
are much smaller than
p
,we
can view Algorithm 2.7 as a linear algorithm in the sample size
p
. As to Algorithm-
IFSC, it must compute and store the association matrix for each pair of samples, so
the computational complexity of Algorithm-IFSC is roughly
O
(
Icpn
)
p
2
(
)
. Therefore, for
Fig. 2.3
Illustration of the convergence of IFCM on the car data set








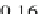



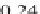

























Search WWH ::

Custom Search