Information Technology Reference
In-Depth Information
(a) (b)
Fig. 3.9.
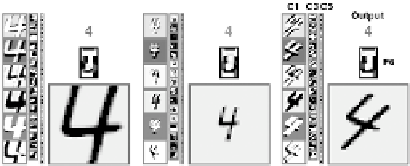
Convolutional neural network activities: (a) isolated digits of different sizes and
orientations can be recognized with LeNet-5; (b) digits need not to be segmented, but can be
recognized in context by a larger SDNN network (images adapted from [134]).
string, but this is computationally expensive. A horizontally enlarged version of the
LeNet-5 network, called space displacement neural network (SDNN), has been de-
veloped that also transforms the last two layers into feature maps. It is trained to
recognize digits in their context. Since the digit positions and sizes are needed to
generate the desired outputs, artificial three-digit blocks and blanks flanked by two
digits were used for training. Figure 3.9(b) shows the response of the SDNN net-
work to an example that is not easy to segment. The outputs of the network indicate
the presence of digits. A postprocessing step is needed to merge multiple outputs
for the same digit and to suppress spurious detections.
3.1.3 Generative Statistical Models
The feed-forward feature extraction used in the previous section is not the only
way to implement discrimination. Since the distribution of images is far from being
uniform, it is also possible to model the probability densities of certain object classes
in image space and use the Bayes rule for inferring the class of an object from an
observation and a generative model [57]. Generative models can also be used for
purposes other than discrimination. For instance, they offer a systematic way to
deal with missing data. Furthermore, generative image models frequently produce
compact image descriptions that allow efficient transmission and storage.
In the following, three examples of hierarchical generative image models are
reviewed: Helmholtz machines, hierarchical products of experts, and hierarchical
Kalman filters.
Helmholtz Machine.
The Helmholtz machine, proposed by Dayan
et al.
[50], is il-
lustrated in Figure 3.10(a). It consists of several layers which contain binary stochas-
tic processing units. These units are turned on with a probability
P
(
s
i
= 1) =
σ
(
a
i
) =
1
1+
e
−
a
i
. Two sets of weights,
φ
and
θ
, connect adjacent layers. Recogni-
tion weights
φ
ij
drive a unit
j
from the activities
s
i
of the units
i
in the next lower
layer. These weights are used in the so called wake-mode of the network to com-
pute higher level representations from the input. Generative weights
θ
kj
work in the
opposite direction. A unit
j
is driven from the units
k
in the next higher layer in
the so called sleep-mode. In this mode, higher-level representations are expanded to
lower-level 'fantasies':


Search WWH ::

Custom Search