Information Technology Reference
In-Depth Information
0.98
0.97
0.96
0.95
0.94
0.93
TRN low noise
TST low noise
TRN medium noise
TST medium noise
TRN high noise
TST high noise
0.92
0.91
0.9
0.89
0.88
0.87
5
10
15
20
iteration
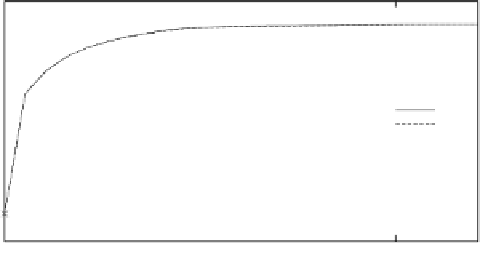
Fig. 9.30.
Confidence over time for the reconstruction from a sequence of degraded MNIST
digits. Performance for the training set (TRN) and the test set (TST) is very similar. Confi-
dence increases most during the first iterations. For higher noise, confidence rises slower and
reaches a lower level than for lower noise.
ations are needed for reconstruction. Towards the end of the sequences, the output
changes are small.
To quantitatively evaluate the performance of the networks, the reconstruction
error, the output changes, and the output confidences were computed for all image
sequences. In all cases, the test set performance is very similar to the performance
on the training set, indicating good generalization.
In Figure 9.26, the mean squared reconstruction error of the training set and the
test set is displayed over time for the three noise variants. The reconstruction error
decreases monotonically until it reaches a level where it remains flat even when
iterated longer than the 16 iterations the networks were trained for. The higher the
noise level is, the slower the error drops and the higher the final error level is.
Figure 9.28 shows the mean squared changes of the output units. The general
behavior is similar to the output error. The changes drop quickly during the first
iterations and decrease more and more slowly. One exception is the bump visible
at iteration 17. It is caused by a jump of the occluding square in the input image
that returns to its initial position after the end of the 16 step sequence. This behavior
shows that the networks are still sensitive to changes in the input and are not locked
to attractors independent of the input.
Finally, the average output confidences are shown in Figure 9.30. The higher
noise network variations remain less confident for a longer time and reach a lower
confidence level than the lower noise variations.
9.6 Conclusions
The experiments in this chapter show that difficult non-linear image reconstruc-
tion tasks can be learned by instances of the Neural Abstraction Pyramid architec-
ture. Supervised training of the networks was done by a combination of BPTT and






































































































































Search WWH ::

Custom Search