Information Technology Reference
In-Depth Information
(a)
(b)
(c)
(d)
(e)
Fig. 9.15.
Filling-in of occlusions: (a) hidden feature array in Layer 0; (e) output feature
array; contributions to the output activity (b) via input projections; (c) via lateral projections
(lines excite themselves and their neighborhood); (d) via backward projections (note the lack
of inhibition at the filled-in line segments).
is such that a reasonable guess of the digit's appearance behind the occluder is pro-
duced. The network reconnects lines, interrupted by the square. It is also able to
extend shortened lines, to close opened loops, and to synthesize corners, junctions,
and crossings. In most cases, the reconstructions are very similar to the originals.
Since the network never saw the original digits, it obviously has acquired some
knowledge about the appearance of typical digits during training.
Figure 9.15 shows the activities of the single hidden feature in the bottom layer
and the output feature array together with its contributions for the same digits after
twelve iterations. One can observe that the hidden units are more active than the
output units. They seem to represent potential lines. The occluding square is still
visible in this feature array since it could hide lines.
The contributions from the input projections to the output feature cells are
mainly excitatory. They look like a copy of the input and contain the square. Weak
inhibition occurs at the edges of the lines and the square. The contributions of lateral
projections are strongly excitatory. Lines excite themselves and their surroundings.
More interesting are the contributions via backward projections. They are strong-
ly inhibitory everywhere, except for the border, where no inhibition is necessary, and
the filled-in line segments. Hence, a detailed description of these segments must ex-
ist at the higher layers of the network.
To quantitatively evaluate the network's performance, the mean squared recon-
struction error and the mean squared output changes were computed for the entire
training set and all test examples. Both are displayed over time in Figure 9.16. The
curves for the two sets are almost identical, indicating good generalization.
The reconstruction error drops quickly during the first iterations and remains
low afterwards. It does not reach zero since a perfect reconstruction is frequently
not possible due to the information loss caused by the occlusion. All the network

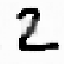






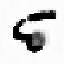
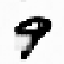

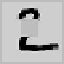




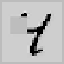


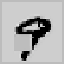






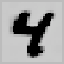














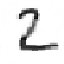


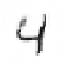

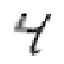


Search WWH ::

Custom Search